pixela4go が v1.9.0 にバージョンアップしました。
pixela4go が v1.9.0 にバージョンアップしました。
Pixela v1.28.0 に対応するバージョンアップとなります。
v1.9.0 アップデート内容
Pixela v1.28.0 で追加された /graphs/<graphID>/pixels API エンドポイントに対応しています。
↓こんな感じで使えます。
client := pixela.New("YOUR_NAME", "YOUR_TOKEN") input := &pixela.GraphUpdatePixelsInput{ ID: String("GRAPH_ID"), Pixels: []PixelInput{ { Date: String("20180101"), Quantity: String("1"), }, { Date: String("20180102"), Quantity: String("2"), }, }, } result, err := client.Graph().UpdatePixels(input)
現場からは以上です。
AWS Lambda 関数のランタイムを Go 1.x => provided.al2 に移行する方法。
はじめに
Lambda 関数のランタイムを Go 1.x => provided.al2 へ移行する方法を記載する。
2ヶ月ほど前、AWS から「Amazon Linux AMI のメンテナンスサポートが 2023 年 12 月 31 日に終了するため、AWS Lambda での Go 1.x ランタイムのサポートも終了する」旨が通知されていた。
既存の Lambda 関数はサポートが終了する 2023/12/31 以降も実行できるようだが、サポートが終了するランタイムをあえて使い続ける理由もないので、Lambda 関数が使うランタイムを Go 1.x => provided.al2 へ移行した。その際に行ったことを記載していく。
お客様の AWS アカウントに現在 Go 1.x ランタイムを使用する 1 つ以上の Lambda 関数があることを確認しましたので、ご連絡いたします。
Amazon Linux AMI のメンテナンスサポートが 2023 年 12 月 31 日に終了するのに合わせて、AWS Lambda での Go 1.x ランタイムのサポートを終了します [1]。Lambda は、provided.al2 ランタイムを使用して Go プログラミング言語を引き続きサポートします。provided.al2 ランタイムを使用すると、AWS Graviton2 プロセッサのサポートや、より小さなデプロイパッケージとより高速な関数呼び出しパスによる効率的な実装など、go1.x ランタイムに比べていくつかの利点があります。詳細については、ブログ記事 [2] を参照してください。
Lambda ランタイムサポートポリシー [3] で説明されているように、Lambda での言語ランタイムのサポートの終了は 2 段階で行われます。2023 年 12 月 31 日以降、Lambda は Lambda 関数で使用される Go 1.x ランタイムにセキュリティパッチやその他アップグレードを適用しなくなり、Go 1.x を使用する関数は、テクニカルサポートの対象外となります。さらに、Go 1.x ランタイムを使用する新しい Lambda 関数を作成できなくなります。2024 年 1 月 30 日以降、Go 1.x ランタイムを使用して既存の関数を更新することができなくなります。
2023 年 12 月 31 日までに、既存の Go 1.x 関数を provided.al2 ランタイムにアップグレードすることをお勧めします。
サポートの終了は機能の実行には影響しません。関数は引き続き実行されます。しかしながら、AWS Lambda チームによるメンテナンスやパッチ適用がされない、サポートされていないランタイムで実行されることとなります。
Go 1.x => provided.al2 への変更
Go 1.x から provided.al2 へ移行するために必要な作業は、次のとおり。
- 実行ファイルの名前を
bootstrapにする - 使用するランタイムを
Go 1.x=>provided.al2に変更する (当たり前だが) - aws-lambda-go のバージョンを v1.18 以降にアップグレードする。 もともと v1.18 以降を使っている場合は不要
Go 1.x ランタイムを使用している Lambda 関数の確認方法
$ aws lambda list-functions \
--function-version ALL \
--region <リージョン> \
--output text \
--query "Functions[?Runtime=='go1.x'].FunctionArn"
参考サイト
- Update on Amazon Linux AMI end-of-life | AWS News Blog
- Migrating AWS Lambda functions from the Go1.x runtime to the custom runtime on Amazon Linux 2 | AWS Compute Blog
- Release v1.18.0 · aws/aws-lambda-go · GitHub https://dev.classmethod.jp/articles/how-to-migrate-aws-sam-go-lambda-application/
- AWS SAMのGo言語Lambdaアプリケーションのランタイムを更新してみた | DevelopersIO
MySQL でテーブル定義情報を表示する方法。
MySQL でテーブル定義情報を表示する方法を記載する。
MySQL のバージョン。
mysql> SELECT VERSION(); +-----------+ | version() | +-----------+ | 8.0.34 | +-----------+ 1 row in set (0.00 sec)
テーブル内のカラムに関する情報を表示する方法
DESCRIBE ステートメント
DESCRIBE <テーブル名> を実行すると、指定したテーブルのカラムに関する情報を表示できる。
mysql> DESCRIBE servers; +-------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+----------+------+-----+---------+----------------+ | ID | int | NO | PRI | NULL | auto_increment | | Name | char(35) | NO | | | | | CountryCode | char(3) | NO | MUL | | | | District | char(20) | NO | | | | | Population | int | NO | | 0 | | +-------------+----------+------+-----+---------+----------------+ 5 rows in set (0.00 sec)
DESCRIBE の省略系の DESC もある ((DESC ステートメント自体が SHOW COLUMNS ステートメントのシノニムである))
DESC のほうがタイプ数が少なくて済むので、普段使いするにはこちらのほうが楽だろう。
後述する SHOW CREATE TABLE とは違い、テーブルの制約やパーティションに関する情報は表示されないが、カラムに関する情報を得るだけならばこちらで十分ではある。
SHOW CREATE TABLE ステートメント
SHOW CREATE TABLE <テーブル名> を実行すると、指定したテーブルを作成する CREATE TABLE ステートメントを表示できる。
DESCRIBE ステートメントはテーブルのカラムに関する情報のみを得られたが、こちらはテーブルの制約やパーティションに関する情報を得ることができる。
また、任意のテーブルと同じ構造のテーブルを別名で作成したい、といったときにはこちらのほうが楽だろう。
mysql> SHOW CREATE TABLE city; | Table | Create Table | | city | CREATE TABLE `city` ( `ID` int NOT NULL AUTO_INCREMENT, `Name` char(35) NOT NULL DEFAULT '', `CountryCode` char(3) NOT NULL DEFAULT '', `District` char(20) NOT NULL DEFAULT '', `Population` int NOT NULL DEFAULT '0', PRIMARY KEY (`ID`), KEY `CountryCode` (`CountryCode`), CONSTRAINT `city_ibfk_1` FOREIGN KEY (`CountryCode`) REFERENCES `country` (`Code`) ) ENGINE=InnoDB AUTO_INCREMENT=4080 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci | 1 row in set (0.00 sec)
参考サイト
GoLand でコード補完が一切効かなくなってしまったときの対処方法。
はじめに
GoLand でコード補完が一切効かなくなってしまったときの対処方法を記載する。
GoLand のバージョン: 2023.2.3
対処方法
GoLand を再起動する
GoLand を再起動することにより、コード補完が効くようになることがある。
キャッシュをクリアする
GoLand のキャッシュをクリアすると、コード補完が効くようになることがある。
GoLand はコード補完を行うためにプロジェクトファイルをキャッシュしているが、ときどきキャッシュが壊れることがあるようで、結果としてコード補完が効かなくなることがあるらしい。 GoLand のキャッシュを削除 & 再起動することでキャッシュが再作成され、コード補完が効くようになる。 自分の経験上では、これで 100% 解決している。
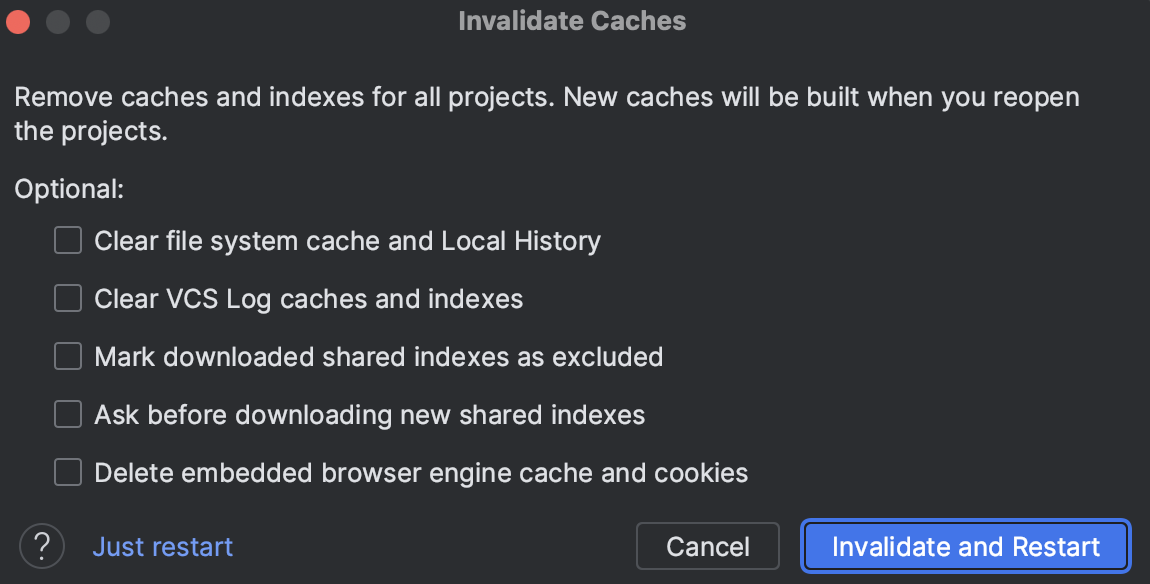
- GoLand のメニューから
File > Invalidate Caches...を実行する Invalidate Cachesダイアログにて、クリアするキャッシュにチェックを付けて、Invalidate and Restartボタンを押す- GoLand が再起動されてインデックスの再作成が始まるので、再作成が完了するまで待つ
JetBrains 製の他の IDE の場合
JetBrain 製の他の IDE でも、同じようにしてコード補完の問題に対処できる。
参考
Mac で Shift+Command+ ], [ の同時押しで tmux のウィンドウ間を移動する方法。
はじめに
tmux を使い始めたばかりだが、とても便利に使っている。
しかしながら、tmux のウィンドウ間を移動するデフォルトのキーバインドは、プレフィックスキーを押した後に Ctrl + n / Ctrl + p を押すというもので、これが少々面倒くさいと感じていた。
自分の場合、tmux のウィンドウ間の移動はプレフィックスキーを押した後にウィンドウ番号を押す、というキー操作を使うことが多いのだが、1つ次のウィンドウ / 1つ前のウィンドウへの移動は、プレフィックスキーを押すことなくサッと移動したいためだ。
そこで、Safari や多くのアプリケーションで採用されている、Shift+Command+ ], [ の同時押しで tmux のウィンドウ間を移動するようにしたところ、非常に捗るようになった。 このやり方をメモしておく。
tmux のバージョン。
$ tmux -V tmux 3.3a
macOS のバージョン。
$ sw_vers | grep Product ProductName: macOS ProductVersion: 13.5.1
やり方
やり方はごくシンプルで、ターミナルソフトへの Shift+Command+ ], [ キーの入力を、 tmux への プレフィックスキー & Ctrl + n / Ctrl + p に置き換えてしまう、というもの。
キー入力の置き換えには Karabiner-Elements を使う。
具体的には、次の変換ルールを Karabiner-Elements に追加するだけでよい。
自分は iTerm2 を使っているが、bundle_identifiers のところをいじれば、他のターミナルソフトでも同じことができると思う。
ただし、このやり方は Shift+Command+ ], [ の入力を他のキー入力に置き換えてしまうので、同ショートカットキーでの iTerm2 のタブ移動はできなくなってしまう。 しかしながら、個人的にはターミナルソフトを使うときはほとんど tmux を使っているので、ほとんど困ったことはない。
{ "title": "change shift + command + square-bracket to ctrl + square-bracket", "rules": [ { "description": "change shift + command + [ to ctrl + g and p", "manipulators": [ { "type": "basic", "description": "change shift + command + [ to ctrl + g and p if iterm2", "from": { "key_code": "close_bracket", "modifiers": { "mandatory": [ "left_command", "left_shift" ], "optional": ["any"] } }, "to": [ { "key_code": "g", "modifiers": [ "left_control" ] }, { "key_code": "p", "modifiers": [] } ], "conditions": [ { "type": "frontmost_application_if", "bundle_identifiers": [ "^com\\.googlecode\\.iterm2$" ] } ] } ] }, { "description": "change shift + command + ] to ctrl + g and n", "manipulators": [ { "type": "basic", "description": "change shift + command + ] to ctrl + g and n if iterm2", "from": { "key_code": "backslash", "modifiers": { "mandatory": [ "left_command", "left_shift" ], "optional": ["any"] } }, "to": [ { "key_code": "g", "modifiers": [ "left_control" ] }, { "key_code": "n", "modifiers": [] } ], "conditions": [ { "type": "frontmost_application_if", "bundle_identifiers": [ "^com\\.googlecode\\.iterm2$" ] } ] } ] } ] }
参考サイト
自分的 .tmux.conf の設定。
はじめに
tmux はごく一時期だけ使っていたことがあったが、あまり有用性を感じられず、その後はずっと使っていなかった。 少し前からまた使うようにしていて、まだ2週間くらいしか使っていないのだが、とても便利に使っていて、非常に有用性を感じている。
tmux.conf での設定はまだ少ないが、だいぶ使いやすくなったと思うので、内容をメモしておく。
tmux のバージョン。
$ tmux -V tmux 3.3a
macOS のバージョン。
$ sw_vers | grep Product ProductName: macOS ProductVersion: 13.5.1
あと、自分が使っている MacBook Pro は JIS 配列のものになる。
.tmux.conf でのカスタマイズ
プレフィックスキー
プレフィックスキーは Ctrl + b から Ctrl + g に変更した。
キーボード上では g と b は斜めに隣接しているキーではあるのだが、自分の場合は g のほうが b よりも断然押しやすく、手にかかる負担もだいぶ小さく感じる。
個人的には「プレフィックスキーを押すのがダルい」と感じていたのだが、Ctrl + g に変えてからはあまり気にならなくなった。
また、プレフィックスキーの候補はいくつかあったが、Ctrl + g は Mac のシステムショートカットキーや他のアプリと競合しない *1 ことも決め手となった。左手だけで押せるのもよい。
unbind C-b set -g prefix C-g
プレフィックスキーを押した後、コマンドを連続入力できる長さ
プレフィックスキーを押した後、コマンドを連続入力できる時間を1000ミリ秒に変更した。
プレフィックスキーを押した後、デフォルトでは 500ミリ秒の間はコマンドを連続入力できるが、ウィンドウを複数のペインに分割している場合等、パッと移動先のキーを打てないことがあったため。 もう少し短くてもいいかもしれない。
set -g repeat-time 1000
ウィンドウ、ペインのインデックスは1から始める
ウィンドウ、ペインのインデックスは1から始めるように変更した。 ターミナルソフトは iTerm2 を使っているのが、iTerm2 ではタブ番号は1から始まるため、それに合わせた形になる。
set -g base-index 1 set -g pane-base-index 1
あと、ウィンドウを閉じたときにインデックスが詰まるようにしている。
set -g renumber-windows on
ペインの操作
ペインを | で水平分割、- で垂直分割するように変更した。
bind -r | split-window -h -c '#{pane_current_path}'
bind -r - split-window -v -c '#{pane_current_path}'
ペインの移動を Vim ライクなキーバインドで行えるように変更した。
bind -r h select-pane -L bind -r j select-pane -D bind -r k select-pane -U bind -r l select-pane -R
ペインのサイズ調整を Vim ライクなキーバインドで行えるように変更した。
bind -r H resize-pane -L 5 bind -r J resize-pane -D 5 bind -r K resize-pane -U 5 bind -r L resize-pane -R 5
また、Ctrl + z でペインを最大化 / 元に戻せるようにしてある。
bind -n C-z resize-pane -Z
新規のウィンドウをカレントディレクトリで開く
新規のウィンドウを開く際、カレントディレクトリが作業ディレクトリになるようにした。
bind c new-window -c '#{pane_current_path}'
マウスでスクロールできるようにする
マウスホイールでスクロールできるように変更した。
マウスをホイールすると、デフォルトではコマンド履歴をスクロール (?) するようになっているが、バッファをスクロールするようにした。
set -g mouse on set -g terminal-overrides 'xterm*:smcup@:rmcup@'
ステータスラインをいい感じにする
ステータスラインがいい感じになるように、最小限だが変更した。
set -g status-justify "centre" set -g status-bg green setw -g window-status-current-style fg=default,bg=magenta set -g status-interval 5
コピー操作
コピーモードに入った後、Vim ライクなキーバインドで操作できるように変更した。
setw -g mode-keys vi
デフォルトでは Space で範囲選択を開始するが、Vim ライクに v で範囲選択を開始するように。
bind -T copy-mode-vi v send-keys -X begin-selection
デフォルトでは Enter で選択範囲をコピーするが、Vim ライクに y で範囲選択をクリップボードにコピーするように。
bind -T copy-mode-vi y send-keys -X copy-pipe-and-cancel "pbcopy"
通常の範囲選択 / 矩形選択の切り替えを、Vim ライクに Ctrl + v で範囲選択を開始するように。
bind -T copy-mode-vi C-v send-keys -X rectangle-toggle
Shift+Command+ ], [ の同時押しで tmux のウィンドウ間を移動する
個人的には、tmux が最高に手に馴染むようになった設定 → Mac で Shift+Command+ ], [ の同時押しで tmux のウィンドウ間を移動する方法。
参考サイト
Pixela の CLI ツール pa が v1.9.0 にバージョンアップしました。
Pixela の CLI ツール pa が v1.9.0 にバージョンアップしました。
v1.9.0 アップデート内容
Pixela v1.27.0 に対応するバージョンアップとなります。
具体的には、graph stats サブコマンドで取得できる情報に maxDate, minDate, yesterdayQuantity フィールドが追加されています。
自分は仕事で残業した時間を Pixela に記録しているんですが、最長の残業時間を記録したブラックな日がいつなのか、一目で分かってしまってしまいます。
残業時間はともかく、Pixela の1ユーザーとしては、maxDate, minDate の2つは便利だなと感じることが多いです。
pa を使われている方には、ぜひ v1.9.0 にアップデートして、Pixela v1.27.0 で追加されたフィールドを試してみていただきたいですね。
$ pa graph stats --id <残業記録> | jq
{
"totalPixelsCount": 884,
"maxQuantity": 10,
"maxDate": "2019-08-03",
"minQuantity": 0,
"minDate": "2018-06-01",
"totalQuantity": 1810,
"avgQuantity": 2.05,
"todaysQuantity": 1,
"yesterdayQuantity": 0
}
v1.9.0 へのアップグレード方法
Homebrew を使っている場合は、次のコマンドにてアップグレードできます。
$ brew update && brew upgrade pa
go install コマンドでアップグレードすることもできます。
$ go install github.com/ebc-2in2crc/pa/cmd/pa@latest
現場からは以上です。