pixela4go が v1.8.0 にバージョンアップしました。
pixela4go が v1.8.0 にバージョンアップしました。
Pixela v1.27.0 に対応するバージョンアップとなります。
v1.8.0 アップデート内容
Pixela v1.27.0 で /stats API に追加された、maxDate, minDate, yesterdayQuantity の3つのフィールドに対応しています。
Pixela の1ユーザーとしては、maxDate, minDate の2つは便利だなと感じることが多いです。
pixela4go を使われている方には、ぜひ v1.8.0 にアップデートして、Pixela v1.27.0 で追加されたフィールドを試してみていただきたいですね。
現場からは以上です。
GoLand の Find Usages 機能で、プロダクションコード / テストコードだけを検索する方法。
はじめに
JetBrains 製の Go 言語向け IDE の GoLand に搭載されている Find Usages 機能で、プロダクションコード / テストコードだけを検索する方法について記載する。
GoLand の Find Usages 機能は、変数を参照 / 値を設定したり、関数やメソッドを呼び出している箇所を調べられる機能で、とても便利。 しかしながら、変数や関数の参照元 / 呼び出し元を調べる際、デフォルトでは「プロダクションコードからの参照だけを調べたい」「テストコードからの呼び出しだけを調べたい」ということができず、少々不便さを感じる *1
でも、GoLand でも少し設定を追加してあげると、プロダクションコード / テストコードだけを検索できるようになる。 以下、その設定方法について記載していく。
Find Usages 機能で、プロダクションコード / テストコードだけを検索する方法
Preferences > Settings > Appearance & Behavior > Scopes にて、次の2つのスコープを追加する。
- プロダクションコードだけを検索するスコープ
- Name:
Project Production Files - Pattern:
file:*/&&!file:vendor//*&&!file:*_test.go
- Name:
- テストコードだけを検索するスコープ
- Name:
Project Test Files - Pattern:
file:*/&&!file:vendor//*&&file:*_test.go
- Name:
あとは、Find Usages 機能を使う際に目的に応じたスコープを指定することによって、プロダクションコード / テストコードだけを検索することができる。
↓スコープ: All Places を指定したとき
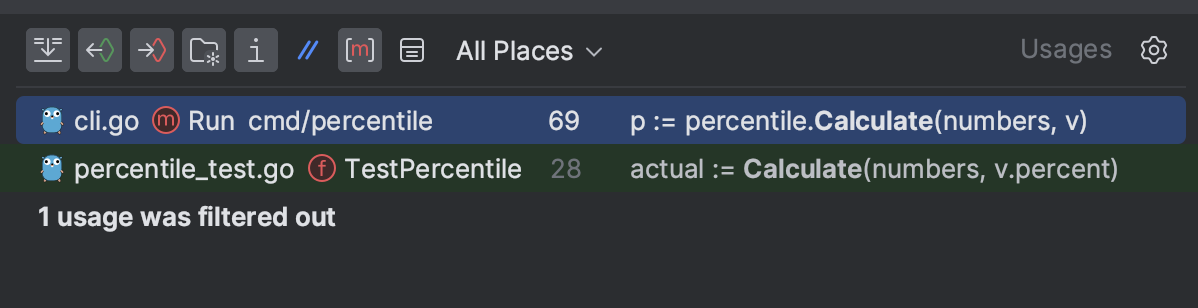
↓スコープ: Project Production Files を指定したとき

↓スコープ: Project Test Files を指定したとき

以上。
参考サイト
AWS Elastic Beanstalk にて構築した環境にアプリケーションをデプロイする際、更新処理がタイムアウトしてしまう事象の解消方法。
はじめに
AWS の Elastic Beanstalk にて構築した環境にアプリケーションをデプロイする際、Beanstalk 環境の更新処理がタイムアウトしてしまう事象が発生した。
結論としては、アプリケーションサーバーをホストしている EC2 インスタンスを入れ替えることで、事象が解消した。
この事象を解消するために行ったこと、調査したことを記載していく。
事象
AWS の Elastic Beanstalk にて構築した環境にアプリケーションをデプロイする際、Beanstalk 環境の更新処理がタイムアウトしてしまう事象が発生した。
INFO Environment update is starting. INFO Deploying new version to instance(s). INFO Environment health has transitioned from Ok to Info. Application update in progress on 1 instance. 0 out of 1 instance completed (running for 30 seconds). ERROR During an aborted deployment, some instances may have deployed the new application version. To ensure all instances are running the same version, re-deploy the appropriate application version. ERROR Failed to deploy application. ERROR Unsuccessful command execution on instance id(s) '<インスタンス ID>'. Aborting the operation. INFO Command execution completed on all instances. Summary: [Successful: 0, TimedOut: 1]. WARN The following instances have not responded in the allowed command timeout time (they might still finish eventually on their own): [<インスタンス ID>]. WARN Environment health has transitioned from Info to Warning. Application update is aborting (running for 14 minutes).
また、アプリケーションのデプロイ以外の操作ではどうなるか? を確認するためにアプリケーションサーバーを再起動したところ、やはり Beanstalk 環境の更新処理がタイムアウトしてしまうことが分かった。 次のような挙動から、アプリケーションサーバーをホストしている EC2 インスタンスにて異常が発生している可能性が高いと想定した。
- 事象が発生している Beanstalk 環境のアプリケーションサーバーの再起動は、普段であれば数十秒もかからずに完了する
- Beanstalk 環境の更新ログの内容が、アプリケーションのデプロイに失敗している際のログと同じような内容になっている
INFO restartAppServer is starting. INFO Environment health has transitioned from Ok to Info. Application restart in progress (running for 4 seconds). ERROR Unsuccessful command execution on instance id(s) '<インスタンス ID>'. Aborting the operation. INFO Command execution completed on all instances. Summary: [Successful: 0, TimedOut: 1]. WARN The following instances have not responded in the allowed command timeout time (they might still finish eventually on their own): [<インスタンス ID>]. INFO Environment health has transitioned from Info to Ok. Application restart completed 57 seconds ago and took 14 minutes.
次に、アプリケーションサーバーをホストしている EC2 インスタンスのログを調べた。
アプリケーションサーバーをホストしている EC2 インスタンスに SSH ログインし、各種ログを調べたところ、/var/lib/log/message にて、cfn-hup.service が停止 / 起動を繰り返していることを示唆するログが出力されていた。
cfn-hup.service は、Beanstalk の環境を更新する際、ユーザーが指定した操作を実行するデーモンのようで、サーバーのデプロイがタイムアウトしてしまうのは、cfn-hup.service が停止 / 起動を繰り返していて、ユーザーが指定した操作が実行されていない可能性が高そう。
The cfn-hup helper is a daemon that detects changes in resource metadata and runs user-specified actions when a change is detected. This allows you to make configuration updates on your running Amazon EC2 instances through the UpdateStack API action.
↓ /var/lib/log/message に出力されていた、cfn-hup.service が停止 / 起動を繰り返しているログ
systemd: cfn-hup.service: main process exited, code=exited, status=1/FAILURE systemd: Unit cfn-hup.service entered failed state. systemd: cfn-hup.service failed. systemd: cfn-hup.service holdoff time over, scheduling restart. systemd: Stopped This is cfn-hup daemon. systemd: Starting This is cfn-hup daemon... systemd: Started This is cfn-hup daemon.
事象を解消するために行ったこと
ユーザーが指定した操作がタイムアウトしてしまう原因は、cfn-hup.service の異常動作にある可能性が高そう。 ということは、cfn-hup.service を再起動することで事象が解消できそうだが、すでに cfn-hup.service が停止 / 開始を繰り返している状態のため、cfn-hup.service を再起動しても事象が解消されない可能性がある *1
今回は、アプリケーションサーバーをホストしている EC2 インスタンスを入れ替えて、事象を解消した *2
事象が発生していたアプリケーションサーバーは部内でのみ使われているもので、多少ダウンタイムが発生してもまったく問題がないものではあったが、ダウンタイムを極小化するため、次のようにして EC2 インスタンスを入れ替えた。
- アプリケーションサーバーをホストする EC2 インスタンスはもともと1台だったが、1台増やして2台にする
- 元々の EC2 インスタンスを停止する
- アプリケーションサーバーをホストする EC2 インスタンスを1台減らし、2台→1台にする
- 残った1台の EC2 インスタンスは、cfn-hup.service は問題なく稼働しているということ
以上。
参考サイト
パーセンタイル値を計算する percentile コマンドを作りました。
What is percentile コマンド?
データ分析において、パーセンタイル値はしばしば重要な指標となります。
percentile コマンドは、ファイルや標準入力から数値を読み込み、パーセンタイル値を表示する CLI プログラムです。
percentile コマンドの特長
percentile コマンドには、次のような特徴があります。
- ファイルおよび標準入力から数値を読み込み、読み込んだ数値のパーセンタイル値を表示する
- 読み込んだ数値はデフォルトでソートされるため、事前にソートする必要がない
- 表示するパーセンタイル値は、デフォルトでは p25, p50, p75, p90, p95, p99 だが、オプションで指定することができる
- パーセンタイル値はデフォルトでは切り捨てられるが、切り捨てないようにオプションで指定できる
使い方の実行例
percentile コマンドを実行する例を示します。
ファイルから数値を読み込む
percentile <ファイル> と実行すると、ファイルから読み込んだ数値のパーセンタイルを表示します。
$ percentile <(seq 1 100) p25: 25 p50: 50 p75: 75 p90: 90 p95: 95 p99: 99
標準入力から数値を読み込む
<他のコマンド> | percentile - と実行すると、標準入力から読み込んだ数値のパーセンタイルを表示します。
$ seq 1 100 | percentile - p25: 25 p50: 50 p75: 75 p90: 90 p95: 95 p99: 99
表示するパーセンタイル値を指定する
表示するパーセンタイル値は、デフォルトでは p25, p50, p75, p90, p95, p99 ですが、-p オプションで表示するパーセンタイル値を指定できます。
表示するパーセンタイル値が複数ある場合は、-p 25,50 のようにカンマで区切ります。
$ seq 1 100 | percentile -p 25,50 - p25: 25 p50: 50
パーセンタイル値を切り捨てない
表示するパーセンタイル値は、デフォルトでは切り捨てられて整数になりますが、-r オプションを指定すると小数点第1位までが表示されます。
$ seq 1 100 | percentile -r - p25: 25.5 p50: 50.5 p75: 75.5 p90: 90.5 p95: 95.5 p99: 99.5
インストール方法
percentile をインストールするには、以下の方法があります。
開発者向け
Go 言語の開発環境が整っている場合は、次のコマンドを実行することにより、percentile コマンドをインストールできます。
$ go install github.com/ebc-2in2crc/percentile/cmd/percentile@latest
手動でのインストール
https://github.com/ebc-2in2crc/percentile/releases にアクセスし、お使いの OS 向けの実行ファイルをダウンロードできます。
Homebrew
Homebrew を使う場合は、次のコマンドを実行することにより、percentile コマンドをインストールできます。
$ brew install ebc-2in2crc/tap/percentile
動機
最近、ちょっとしたデータ分析をする際に、パーセンタイル値を求めることが何回かありました。
CLI でパーセンタイル値を求められるコマンドを探したところ、そういったツールはいくつかあったのですが、次のようなところが自分の使い方にはマッチしませんでした。
- 数値の読み込み元として、ファイルと標準入力の両方をサポートしていない
- 表示するパーセンタイル値が固定されてしまっている
そこで、パーセンタイル値を計算 & 表示するコマンドをサッと実装してしまいました *1
まとめ
percentile の開発やバグレポート、質問などがあったら、GitHub のリポジトリに issue や PR を作ったり、Twitter でお気軽にお声がけいただけたら嬉しいです。
ということで、 percentile コマンドの紹介でした。
*1:また、再発明をしてしまいました
ab コマンド (ApacheBench) の自分的チートシート。
ab コマンド (ApacheBench) の自分的チートシートをメモしておく。
ab コマンドのバージョン。
$ ab -V This is ApacheBench, Version 2.3 <$Revision: 1901567 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, https://www.zeustech.net/ Licensed to The Apache Software Foundation, https://www.apache.org/
このエントリーを書いた動機
システムの性能を測定するときは k6 を使うことが多く、ApacheBench はほとんど使ったことがなかった。 しかしながら、雑にシステムに負荷をかけたり、非常にざっくりとした性能指標を見る程度であれば、ApacheBench で事足りることもあったりするし、なにより手軽に利用できるのがよいなー、と思った。 でも、めったに使わないとも思ったので、次に使うときに使い方をさっと調べられるように、備忘録代わりに書いた。
ab コマンドのチートシート
基本的な使い方
$ ab -c <並列数> -n <リクエスト数> <URL>
たとえば、次のコマンドでは、https://localhost:8080/ に対して10並列でリクエストを1000回送信する。
$ ab -c 10 -n 1000 https://localhost:8080/
リクエスト数を指定する
-n オプションにて、リクエスト数を指定できる。
# リクエストを100回送信する $ ab -n 100 https://localhost:8080/ # デフォルトは1回だけ送信する。次の2つのコマンドは、どちらもリクエストを1回だけ送信する $ ab https://localhost:8080/ $ ab -n 1 https://localhost:8080/
並列数を指定する
-c オプションにて、リクエストの並列数を指定できる。
# 10並列でリクエストを1000回送信する $ ab -c 10 -n 1000 https://localhost:8080/ # デフォルトは1並列。次の2つのコマンドの並列数はどちらも1となる $ ab https://localhost:8080/ $ ab -c 1 https://localhost:8080/
タイムアウトを指定する
-t オプションにて、ベンチマークの最大実行時間を秒単位で指定できる。
-t オプションを指定した場合、所定の回数分のリクエストを送信するか、あるいは指定した時間が過ぎるとコマンドの実行が終了する。
なお、-n オプションを指定していない場合は -n 50000 が指定されたものとして動作する。
# リクエストを10000回送信する # 60秒が経過すると、リクエストの送信が完了していなくても終了する $ ab -n 10000 -t 60 https://localhost:8080/
一定時間、負荷をかけ続ける
-n オプションと -t オプションを組み合わせて、一定時間、負荷をかけ続けることができる。
-n オプションで非常に大きなリクエスト数を指定するのがポイント。
# 60秒間、100並列でリクエストを送信し続ける # ただし、リクエストを 10000000 回送信したらコマンドの実行が完了してしまう # その場合は -n オプションにもっと大きな値を指定するとよい $ ab -c 100 -n 10000000 -t 60 https://localhost:8080/
HTTP ヘッダーを指定する
-H オプションにて、HTTP ヘッダーを指定できる。
# Accept-Encoding を指定する $ ab -H 'Accept-Encoding: gzip, deflate' https://localhost:8080/ # 複数の HTTP ヘッダーも指定できる $ ab -H 'Accept-Encoding: gzip, deflate' -H 'Cache-Control: max-age=0' https://localhost:8080/
HTTP Keep-Alive を有効にする
-k オプションを指定すると HTTP Keep-Alive を有効にできる。
# HTTP Keep-Alive を有効にする $ ab -k https://localhost:8080/ # デフォルトは HTTP Keep-Alive は無効となる $ ab https://localhost:8080/
出力のフォーマット
ab コマンドを実行すると次のように出力される。
$ ab -n 10 https://localhost:8080/
This is ApacheBench, Version 2.3 <$Revision: 1901567 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, https://www.zeustech.net/
Licensed to The Apache Software Foundation, https://www.apache.org/
Benchmarking localhost:8080 (be patient).....done
Server Software:
Server Hostname: localhost:8080
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-ECDSA-CHACHA20-POLY1305,384,256
Server Temp Key: ECDH X25519 253 bits
TLS Server Name: localhost:8080
Document Path: /
Document Length: 4 bytes
Concurrency Level: 1
Time taken for tests: 0.293 seconds
Complete requests: 10
Failed requests: 0
Total transferred: 248 bytes
HTML transferred: 4 bytes
Requests per second: 3.41 [#/sec] (mean)
Time per request: 293.165 [ms] (mean)
Time per request: 293.165 [ms] (mean, across all concurrent requests)
Transfer rate: 0.83 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 190 190 0.0 190 190
Processing: 103 103 0.0 103 103
Waiting: 102 102 0.0 102 102
Total: 293 293 0.0 293 293
Percentage of the requests served within a certain time (ms)
50% 231
66% 233
75% 234
80% 236
90% 258
95% 258
98% 258
99% 258
100% 258 (longest request)
この出力のうち、性能指標に関わる項目の意味は次のとおり。
| 項目 | 説明 |
|---|---|
| Concurrency Level | 並列数 |
| Time taken for tests | テストにかかった時間 (秒) |
| Complete requests | 成功したリクエスト数 |
| Failed requests | 失敗したリクエスト数 |
| Total transferred | 合計転送量 (バイト) |
| HTML transferred | HTML ドキュメントの転送量 (バイト) |
| Requests per second | 1秒あたりの平均リクエスト数 |
| Time per request | 1リクエストあたりの平均所要時間 (ミリ秒) |
| Transfer rate | 転送速度 (KB/秒) |
Connection Times (ms) の部分はリクエストの処理に要した時間の内訳。
項目ごとに左から、最小値、平均値、標準偏差、中央値、最大値となっている。
| 項目 | 説明 |
|---|---|
| Connect | クライアントがサーバーに接続するのにかかった時間 |
| Processing | リクエストが送信されてから、サーバーの応答が完了するまでの時間 |
| Waiting | リクエストが送信されてから、サーバーから最初のバイトが受信されるまでの時間 |
Percentage of the requests 〜 の部分は、パーセンタイルでのリクエストの応答時間。
実行結果を CSV ファイルに出力する
-e オプションで出力先のファイル名を指定し、実行結果を CSV ファイルに出力できる。
$ ab -n 10 -e result.csv https://localhost:8080/ ... 省略 ...
CSV ファイルは次のようなフォーマットで出力される。
$ cat result.csv Percentage served,Time in ms 0,184.886 1,184.886 2,184.886 ... 省略 ... 99,0.000 100,241.682
実行結果を TSV ファイルに出力する
-g オプションで出力先のファイル名を指定し、実行結果を CSV ファイルに出力できる。
$ ab -n 10 -g result.tsv https://localhost:8080/ ... 省略 ...
TSV ファイルは次のようなフォーマットで出力される。
$ cat result.tsv starttime seconds ctime dtime ttime wait Thu May 18 19:50:48 2023 1684407048 96 100 196 100 Thu May 18 19:50:48 2023 1684407048 105 109 215 109 Thu May 18 19:50:48 2023 1684407048 107 109 216 109 Thu May 18 19:50:47 2023 1684407047 107 109 216 109 Thu May 18 19:50:47 2023 1684407047 110 112 222 112 Thu May 18 19:50:48 2023 1684407048 113 114 227 114 Thu May 18 19:50:48 2023 1684407048 115 116 231 116 Thu May 18 19:50:46 2023 1684407046 115 117 232 117 Thu May 18 19:50:47 2023 1684407047 116 119 235 119 Thu May 18 19:50:47 2023 1684407047 126 127 253 126
コマンド、キーボードショートカットで Mac を再起動する方法。
マウスを使わずに、コマンド、キーボードショートカットで Mac を再起動する方法をメモしておく。
shutdown コマンドで Mac を再起動する
ターミナルソフトで次のコマンドを入力する。 大概はこれでなんとかなる。
$ sudo shutdown -r now
キーボードショートカットで Mac を再起動する
キーボードショートカットで Mac を再起動するには、control ボタン、command ボタン、電源ボタンを同時押しする。 このキーボードショートカットは、誤操作を避けるためにある程度長めに押す必要がある。実際に Mac が再起動するまで押し続けるとよい。
大概は shutdown コマンドを使う方法でなんとかなるが、ユーザーリソースの設定を誤ってしまう等でシステム管理用のコマンドすら実行できなくなってしまった場合は、キーボードショートカットで Mac を再起動するしかない。
参考サイト
sed コマンドを使って cat, grep, tr, wc, head, tail コマンドを再発明してみた。
社内でシェルスクリプトの活用が増えるといいなー、と思って、とっかかりになるようなパズル的なものを考えてみた。 シェルスクリプトに興味をもってもらうことが目的なので、いわゆる「シェル芸」のような結構手応えがあるものではなく、一部を除いてはごく簡単なものになっていると思う。
sed コマンドのバージョン
macOS に GNU sed をインストールして使っている。
$ sed --version sed (GNU sed) 4.8
sed コマンドでいろんなコマンドを再発明する
cat
cat コマンドの再発明、そして他のコマンドの再発明には、次のファイルを入力として使う。
$ cat numbers.txt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
sed コマンドは式を与えられない場合、入力をそのまま出力するので、それを利用する。
$ sed '' numbers.txt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
grep
次のようにすると grep コマンドを再発明できる。
-nオプションを指定し、出力を抑制する- 出力したい行 (アドレス) を正規表現で指定し、マッチしたら
pコマンドで出力する
$ grep 3 numbers.txt 1 2 3 13 14 15 $ sed -n /3/p numbers.txt 1 2 3 13 14 15
tr
次のようにすると tr コマンドを再発明できる。
yコマンドを使って文字列内の文字を変換する
$ tr [123] [abc] < numbers.txt a b c 4 5 6 7 8 9 a0 aa ab ac a4 a5 a6 a7 a8 $ sed 'y/123/abc/' numbers.txt a b c 4 5 6 7 8 9 a0 aa ab ac a4 a5 a6 a7 a8
wc
次のようにすると wc -l コマンドを再発明できる。
-nオプションを指定し、出力を抑制する- 入力の最終行をマッチさせて
=コマンドを実行し、マッチした行つまり最終行の行番号を出力する
$ wc -l numbers.txt 6 numbers.txt $ sed -n '$=' numbers.txt 6
head
次のようにすると head コマンドを再発明できる。
- 表示したい最終行 (入力全体での2行目) をマッチさせて
qコマンドを実行し、そこでスクリプトを終了する
$ head -n 2 numbers.txt 1 2 3 4 5 6 $ sed '2q' numbers.txt 1 2 3 4 5 6
別解。
-nオプションを指定し、出力を抑制する- 表示したい最初の行から最終行までをマッチさせて、
pコマンドで出力する
$ sed -n '1,2p' numbers.txt 1 2 3 4 5 6
tail
次のようにすると tail コマンドを再発明できる *1
ここでは、ファイルの末尾2行を表示させている。
:aにてラベルを定義する。あとでジャンプのターゲットとして使う$q;N;3,$D;ba: この部分には以下の4つのコマンドが含まれている$q: 直前に読み込んだ行が入力の最終行である場合、それまでの行を出力してqコマンドでスクリプトを終了する。 これにより、最後の2行まで読み込んだ後に出力されるようになる。N: 次の行を読み込んでパターンスペースに追加する。 これにより、複数の行をパターンスペースに保持させ、最終的には最後の2行がパターンスペースに格納される。3,$D: パターンスペース内の行が3行以上になった場合、最も古い行 (つまり先頭の行) を削除する。 さらにDコマンドの副作用として新しい入力行を読み込み、スクリプトが最初から実行される。 これにより、最後の2行だけがパターンスペースに保持されるようになる。ba:bコマンド (分岐コマンド) を実行して定義済みのラベルaにジャンプする。 これにより、スクリプトが最初から繰り返されるようになる。
$ tail -n 2 numbers.txt 13 14 15 16 17 18 $ sed ':a;$q;N;3,$D;ba' numbers.txt 13 14 15 16 17 18
以上。
*1:パッと思いつかなくて、コマンドのリファレンスを調べたり ChatGPT に相談しながらやってみた