AWS CLI v2 のぺージャーを無効にする方法。
AWS CLI v2 のぺージャーを無効にする方法をメモしておく。
$ aws --version aws-cli/2.0.30 Python/3.7.4 Darwin/19.5.0 botocore/2.0.0dev34 $ docker container run --volume ~/.aws:/root/.aws --rm --env AWS_PAGER= amazon/aws-cli --version aws-cli/2.0.30 Python/3.7.3 Linux/4.19.76-linuxkit botocore/2.0.0dev34
AWS CLI v2 のぺージャーを無効にする方法
AWS CLI v2 はデフォルトでページャーを使うようになった
AWS CLI バージョン 2 では、クライアント側のページャープログラムを出力に使用できます。デフォルトでは、この機能はオペレーティングシステムのデフォルトのページャープログラムを介してすべての出力を返します。
AWS CLI v1 はデフォルトではページャーは使わなかったけど AWS CLI v2 はデフォルトで OS のデフォルトのページャーを使うようになった。
個人的にはページャーが必要なときは自分で使うから AWS CLI v2 の仕様変更はあまり嬉しみがないというかむしろ余計なお世話のように感じるけど、変わってしまったものは仕方ないので AWS CLI v2 がページャーを使わなくしていく。
config ファイルでページャーを無効にする
AWS CLI v2 はページャーを config ファイルの cli_pager オプションに設定しておくとそのページャーを使って出力するけど cli_pager オプションを空の文字列にしておくとページャーを使わなくなる。
[default] cli_pager=
config ファイルを直接いじるかこんな感じのコマンドを実行すればいい。 自分が普段使ってる環境は config を設定しておくのがよさそう。
$ aws configure set cli_pager '' $ cat ~/.aws/config [default] cli_pager= # 省略
環境変数でページャーを無効にする
自分が普段使ってる環境は config を設定しておくのが手軽だけどシェルスクリプトを作って他の人に使ってもらったり CI で動かすときはページャーの使用は config の設定に依存したくないと思うので環境変数でページャーを無効にしていく。
AWS CLI v2 はページャーを AWS_PAGER 環境変数に設定しておくとそのページャーを使って出力するけど AWS_PAGER 環境変数を空の文字列にしておくとページャーを使わなくなる。
export AWS_PAGER= みたいな感じで AWS_PAGER 環境変数をエクスポートしておくとよい。
$ export AWS_PAGER= $ aws ec2 describe-regions
環境変数を一時的に設定してページャーを無効にする
AWS_PAGER をエクスポートして環境を汚したくないときは環境変数を一時的に設定してページャーを無効にしていく。
$ env AWS_PAGER= aws ec2 describe-regions
AWS CLI v2 を Docker で使ってるなら docker container run するときに AWS_PAGER 環境変数を --env AWS_PAGER= みたいに指定していく。
$ docker container run --volume ~/.aws:/root/.aws --rm --env AWS_PAGER= amazon/aws-cli ec2 describe-regions
以上。
参考サイト
標準入力を Docker コンテナに接続する方法。
標準入力を Docker コンテナに接続する方法のメモ。
標準入力を Docker コンテナに繋ぐ方法
結論
一言で書いてしまうと docker container run とか docker container exec するときに -i フラグを指定すると標準入力が Docker コンテナに接続する。
実際にやってみる
こんな感じの Dockerfile を用意しておく。
FROM alpine:3.12 CMD ["cat"]
ざっくりと Dockerfile をビルドする。
$ docker image build -t docker-cat .
docker container run を -i フラグを指定しないで実行すると標準入力は Docker コンテナに接続しない。
$ echo 'Hello World!' | docker container run --rm docker-cat # 何も出力しない
docker container run を -i フラグを指定して実行すると標準入力は Docker コンテナに接続する。
$ echo 'Hello World!' | docker container run --rm -i docker-cat Hello World!
以上。
-it みたいな感じで -i フラグと -t をセットで指定しちゃうことが多くて -i フラグの意味がよく分かってなかったけど今は分かってると思う。help を見るの大事。
$ docker container run --help
Go のテンプレートの使い方のメモ。
Go のテンプレートを軽く調べたのでメモ。
Go のテンプレート
とりあえず使ってみる
Go のテンプレートはこんな感じで使う。
package main import ( "os" "text/template" ) type Fruit struct { Name string Count int } func main() { text := `持っている果物: {{.}}` tmpl, err := template.New("test").Parse(text) if err != nil { panic(err) } fruit := Fruit{ Name: "リンゴ", Count: 1, } err = tmpl.Execute(os.Stdout, fruit) if err != nil { panic(err) } } // 出力 // 持っている果物: {リンゴ 1}
テンプレートはこんな感じでデータに適用することで実行する。 テンプレートはデータに適用しなくてもいいけど普通はテンプレートを使うときはなにかデータに適用すると思う。
さっきはテンプレートを Fruit 構造体に適用したけどテンプレートは構造体だけじゃなくて配列、スライス、マップ、チャネルとかにも適用できる。
たとえばスライスにはこんな感じで適用する。
package main import ( "os" "text/template" ) func main() { text := `持っている果物: {{.}}` tmpl, err := template.New("test").Parse(text) if err != nil { panic(err) } fruits := []Fruit{ {Name: "リンゴ", Count: 1}, {Name: "マンゴー", Count: 2}, } err = tmpl.Execute(os.Stdout, fruits) if err != nil { panic(err) } } // 出力 // 持っている果物: [{リンゴ 1} {マンゴー 2}]
さっきのコードの {{.}} はテンプレート内で使えるアクションの1つ。
さっきのコードはスライスをそのまま参照して出力したけど、アクションを使うと適用したデータの要素たとえば構造体のフィールドとかマップのキーとかを参照したりテンプレートの実行を制御できる。
さっきのコードのテンプレート内でアクションをこんな感じに使うと構造体のスライスの要素それぞれを参照して出力とかができる。
テンプレートをデータに適用するとデータが走査されていってデータの現在位置は . (ドット) で参照できる。
テンプレート内のアクションを使って条件分岐したりデータを繰り返し処理して目的の出力を得ていくので、だいたいテンプレートの使い方を学ぶ = アクションの使い方を学ぶ感じ。
text := `{{range $index, $element := .}} {{- .Name}} は {{.Count}} 個あります。 {{end}}` // 出力 // リンゴ は 1 個あります。 // マンゴー は 2 個あります。
Actions: アクション
アクションは適用したデータの要素たとえば構造体のフィールドとかマップのキーとかを参照したりテンプレートの実行を制御する。
アクションは {{ と }} で囲んで記述する。
さきほどのコードは {{range $index, $element := .}}, {{.Count}} とか {{end}} がアクション。
テンプレート内のアクションじゃないところはそのまま出力するけど、アクションの左の区切り文字 {{ の直後にマイナス記号と半角スペース (-) を記述するとアクションの直前のテキストの末尾のホワイトスペースをトリムする。同じようにアクションの右の区切り文字 }} の直前に半角スペースとマイナス記号 (-) を記述するとアクションの直後のテキストの末尾のホワイトスペースをトリムする。
text := `{{23}} < {{45}} {{23 -}} < {{- 45}}` // 出力 // 23 < 45 // 23<45
アクションはたくさんあるのでそれぞれ書いていく。
comment (コメント)
{{/* a comment */}} と記述したところは出力しない。 コメントは複数行にすることもできる。
text := `{{/* コメントは出力しない */}} Hello Golang! {{- /* コメントは 複数行もできる */}} Hello Template! ` // 出力 // Hello Golang! // Hello Template!
{{ pipeline}} はパイプライン (pipeline) をデフォルトで fmt.Print で出力する。
パイプラインは結構いろいろ書けるので後で少し詳しく書く。
text := `{{.}} {{"リテラルを出力"}} ` // 出力 // [{リンゴ 1} {マンゴー 2}] // リテラルを出力
{{if pipeline}} T1 {{end}} は パイプラインがゼロ値のときは何も出力しない。パイプラインがゼロ値じゃなかったら T1 を出力する。
text := `{{if ""}}出力しない{{end}} {{if "a"}}出力する{{end}} ` // 出力 // 出力する
{{if pipeline}} T1 {{else}} T0 {{end}} はパイプラインがゼロ値のときは T0 を出力してパイプラインがゼロ値じゃなかったら T0 を出力する。
text := `{{if ""}}出力しない{{else}}"" はゼロ値{{end}} {{if "a"}}"a" はゼロ値じゃない{{else}}{{end}} ` // 出力 // "" はゼロ値 // "a" はゼロ値じゃない
{{if pipeline}} T1 {{else if pipeline}} T0 {{end}} は {{if}} - {{else} に別の if を入れこんだやつ。
text := ` {{if ""}}出力しない {{else if 0}}出力しない {{else}}"" と 0 はゼロ値 {{end}}` // 出力 // "" と 0 はゼロ値
{{range pipeline}} T1 {{end}} はパイプラインの要素を繰り返し処理する。
パイプラインは配列、スライス、マップ、あるいはチャネルのいずれかである必要がある。
パイプラインの長さゼロがゼロのときは何も出力しない。
パイプライン要素が繰り返し処理するときドット (.) は現在処理している要素を示す。
text := `{{range .}}{{.}}, {{end}}` _ = tmpl.Execute(os.Stdout, []int{1, 2, 3}) // 出力 // 1, 2, 3,
{{range pipeline}} T1 {{else}} T0 {{end}} は {{range}} と同じだけどパイプラインの要素がないときは T0 を出力する。
text := `{{range .}}{{.}}, {{else}}パイプラインの要素がない{{end}}` _ = tmpl.Execute(os.Stdout, nil) // 出力 // パイプラインの要素がない
{{template "name"}} はテンプレートを名前で指定して nil データに適用と実行する。
text := `{{define "foo"}}*** 事前に定義したテンプレート ***{{end}} {{template "foo"}} {{template "foo"}}` // 出力 // *** 事前に定義したテンプレート *** // *** 事前に定義したテンプレート ***
{{template "name" pipeline}} はテンプレートを名前で指定してドット (.) をパイプラインにセットして適用と実行する。
text := `{{define "foo"}}{{range $index, $element := .}}{{$element}}, {{end}}{{end}} {{template "foo" .}} {{template "foo" .}}` _ = tmpl.Execute(os.Stdout, []int{1, 2, 3}) // 出力 // 1, 2, 3, // 1, 2, 3,
{{block "name" pipeline}} T1 {{end}} は {{define "name"}} T1 {{end}} と {{template "name" pipeline}} を実行する短縮記法。
text := `{{block "foo" .}}*** 事前に定義したテンプレート ***{{end}}` // 出力 // *** 事前に定義したテンプレート ***
{{with pipeline}} T1 {{end}} は {{if}} とだいたい同じだけどパイプラインがドット (.) にセットして実行する。
text := `{{range $index, $element := . -}} {{with $element}}{{.}} はゼロ値じゃない{{end}} {{end}}` _ = tmpl.Execute(os.Stdout, []int{0, 1, 0, 2}) // 出力 // 1 はゼロ値じゃない // 2 はゼロ値じゃない
{{with pipeline}} T1 {{else}} T0 {{end}} は {{with pipeline}} T1 {{end}} と同じだけどパイプラインがゼロ値のときは T0 を出力する。
text := `{{range $index, $element := . -}} {{with $element}}{{.}} はゼロ値じゃない{{else}}ゼロ値{{end}} {{end}}` _ = tmpl.Execute(os.Stdout, []int{0, 1, 0, 2}) // 出力 // ゼロ値 // 1 はゼロ値じゃない // ゼロ値 // 2 はゼロ値じゃない
Arguments: 引数
Arguments は単なる値でいろいろ入れられる。
定数は untyped constant になって nil は untyped nil になる。
text := ` {{print true}} {{print "文字列"}} {{print 1}} {{print 1.5}} {{print .}} {{print nil}}` _ = tmpl.Execute(os.Stdout, []int{0, 1, 0, 2}) // 出力 // true // 文字列 // 1 // 1.5 // [0 1 0 2] // <nil>
ドット (.) はその時のドットの値。
text := `{{.}}` _ = tmpl.Execute(os.Stdout, []int{0, 1, 0, 2}) // 出力 // [0 1 0 2]
$ で始まる変数名。
変数は $ という名前もつけられる。
text := `{{$name := "Alice"}} {{$ := "Bob"}} Hello {{$name}}! Hello {{$}}!` // 出力 // Hello Alice! // Hello Bob!
構造体のフィールド。
.Field の形式で記述する。
.Field1.Field2 みたいにネストして参照できて $x.Field1.Field2 みたいに変数のフィールドも参照できる。
text := `{{.Name}} は {{.Count}} 個あります。` fruit := Fruit{Name: "リンゴ", Count: 1} _ = tmpl.Execute(os.Stdout, fruit) // 出力 // リンゴ は 1 個あります。
マップのキー。
.Key の形式で記述する。
.Field1.Key1.Field2.Key2 みたいにネストして参照できて $x.key1.key2 みたいに変数のキーの値も参照できる。
text := `リンゴは {{.リンゴ}} 個あります。 マンゴーは {{.マンゴー}} 個あります。` m := map[string]int{ "リンゴ": 1, "マンゴー": 3, } _ = tmpl.Execute(os.Stdout, m) // 出力 // リンゴは 1 個あります。 // マンゴーは 3 個あります。
引数のないメソッド。
メソッドは1つか2つの戻り値を返す。
.Field1.Key1.Method1.Field2.Key2.Method2 みたいにネストしてメソッドを呼び出せる。
2つの戻り値を返すときは2つ目の戻り値は error で、2つめの戻り値が nil 以外のときはテンプレートの実行が止まってその erorr が Execute() の戻り値になる。
type Fruit struct { Name string Count int } func (p Fruit) String() (string, error) { s := fmt.Sprintf("%s は %d 個あります。", p.Name, p.Count) return s, nil } text := `{{.String}}` fruit := Fruit{Name: "リンゴ", Count: 1} _ = tmpl.Execute(os.Stdout, fruit) // 出力 // リンゴ は 1 個あります。
引数のない関数。
引数のない関数の戻り値に関しての振る舞いは引数のないメソッドの戻り値と同じ。
text := `{{print "Hello Template!"}}` // 出力 // Hello Template!
カッコ ((, )) でグループ化ができる。
{{print or "" "a" "b"}} テンプレートはエラーになるけど以下のように or をカッコで囲ってグループ化するとちゃんと実行する。
text := `{{print (or "" "a" "b")}}` // 出力 // a
Pipeline: パイプライン
パイプラインはコマンドを パイプ (|) で繋げたもの。
コマンドは単なる値、メソッドあるいは関数で、コマンドは1つまたは2つの値を出力する。 コマンドが2つめの値を出力するとき2つめの出力は erorr で、コマンドの2つめ出力が nil 以外のときはテンプレートの実行が止まってその erorr が Execute() の戻り値になる。
text := `{{"a" | printf "%s"}} {{"a" | printf "%s" | printf "%q"}}` // 出力 // a // "a"
Variables: 変数
変数は {{$variable := pipeline}} の記述で宣言と初期化をする。
宣言済みの変数は {{$variable = pipeline}} の記述で値を割り当てられる。
変数のスコープは変数が {{if}}, {{with}} あるいは {{range}} で宣言すると対応する {{end}} までが変数のスコープになる。
text := `{{$val := "a"}}{{$val}}
{{$val = "b"}}{{$val}}`
// 出力
// a
// b
{{range $index, $element := pipeline}} の記述で pipeline がスライスのときはスライスのインデックスが1つめの変数 $index にセットしてスライスの要素が2つめの変数 $element にセットする。
{{range $index, $element := pipeline}} の記述で pipeline がマッのときはマップのキーが1つめの変数 $index にセットしてマップの要素が2つめの変数 $element にセットする。
このへんの変数名は $index とか $element じゃなくてもいい。
{{range $element := pipeline}} みたいに変数が1つのときは pipeline がスライスのときはスライスの要素が1つめの変数 $element にセットして、pipeline がマップのときはマップの要素が1つめの変数 $element にセットする。このへんの振る舞いは通常の for 文の range の振る舞いと逆なので注意。
Functions: 関数
関数は定義済みの関数とユーザー定義の関数がある。 定義済みの関数をそれぞれ軽く書いて、あとユーザー定義の関数の定義と使い方を書いていく。
定義済みの関数
and は引数のうち最初に見つかったゼロ値を返す。
ゼロ値の引数がないときは最期の引数を返す。
text := `and "a" true 0 1 => {{and "a" true 0 1}} and "a" true 1 => {{and "a" true 1}}` // 出力 // and "a" true 0 1 => 0 // and "a" true 1 => 1
call は最初の引数に残りの引数を渡して実行した結果を返す。
最初の引数は1つまたは2つの戻り値を返す関数であること。 関数が返す2つめの戻り値は erorr で、関数の2つめの戻り値が nil 以外のときはテンプレートの実行が止まる。 あと関数の実引数が仮引数と一致しないときもテンプレートの実行が止まる。
text := `{{call .add 1 2}}` data := map[string]interface{}{ "add": func(a, b int) int { return a + b }, } _ = tmpl.Execute(os.Stdout, data) // 出力 // 3
html は引数を HTML としてエスケープした結果を返す。
text := `{{html "<html>"}}` // 出力 // <html>
index は最初の引数に残りの引数をインデックスとして適用した結果を返す。
最初の引数は配列、スライスまたはマップである必要がある。
text := `{{index . 2}}` _ = tmpl.Execute(os.Stdout, []string{"a", "b", "c"}) // 出力 // c
slice は最初の引数を残りの引数でスライスした結果を返す。
最初の引数は配列、スライスまたは文字列である必要がある。
text := `{{slice . 1 3}}` _ = tmpl.Execute(os.Stdout, []string{"a", "b", "c", "d"})
js は引数を JavaScript としてエスケープした結果を返す。
text := `{{js "<script>alert('hello');</script>"}}` // 出力 // \x3Cscript\x3Ealert(\'hello\');\x3C/script\x3E
len は引数の長さを返す。
text := `{{len .}}` _ = tmpl.Execute(os.Stdout, []string{"a", "b", "c", "d"}) // 出力 // 4
not は引数のブール値の否定を返す。
text := `{{not true}}` // 出力 // false
or は引数のうち最初に見つかった非ゼロ値を返す。
非ゼロ値の引数がないときは最期の引数を返す。
text := `or "" false 1 0 => {{or "" false 1 0}} or "" false 0 => {{or "" false 0}}` // 出力 // or "" false 1 0 => 1 // or "" false 0 => 0
print, println と printf はそれぞれ fmt.Sprint, fmt.Sprintln と fmt.Sprintf のエイリアス。
text := `{{print "Hello Template"}}! {{println "Hello Template"}}! {{printf "Hello %s!" "Template" }}` // 出力 // Hello Template! // Hello Template // ! // Hello Template!
urlquery は引数をクエリストリングとしてエスケープした結果を返す。
text := `{{urlquery "https://golang.org/?lang=ja"}}` // 出力 // https%3A%2F%2Fgolang.org%2F%3Flang%3Dja
text := `eq true true => {{eq true true}} ne true true => {{ne true true}} lt 1 1 => {{lt 1 1}} lt 0 1 => {{lt 0 1}} le 1 1 => {{le 1 1}} le 0 1 => {{le 0 1}} gt 1 1 => {{gt 1 1}} gt 2 1 => {{gt 2 1}} ge 1 1 => {{ge 1 1}} ge 2 1 => {{ge 2 1}}` // 出力 // eq true true => true // ne true true => false // lt 1 1 => false // lt 0 1 => true // le 1 1 => true // le 0 1 => true // gt 1 1 => false // gt 2 1 => true // ge 1 1 => true // ge 2 1 => true
ユーザー定義の関数
ユーザー定義の関数は template.FuncMap を template.Funcs() に渡すと使えるようになる。 template.Funcs(funcMap FuncMap) は template.Parse() よりも前に呼び出す必要がある。
funcs := map[string]interface{}{ "sum": func(numbers []int) int { total := 0 for _, v := range numbers { total += v } return total }, } text := `{{sum .}}` tmpl, err := template.New("test").Funcs(funcs).Parse(text) _ = tmpl.Execute(os.Stdout, []int{1, 2, 3, 4, 5}) // 出力 // 15
ファイルに保存しているテンプレートを読む
ここまではテンプレートはプログラムの中にハードコードしてたけど実際にテンプレートを使うときはテンプレートはファイルに保存しておいてプログラムからテンプレートを読み込んで使うことが多そう。 ファイルに保存しているテンプレートは template.ParseFiles() とか ParseGlob() で読み込んで使っていく。
tmpl, err := template.ParseFiles("header.template", "main.template", "footer.template") if err != nil { panic(err) } err = tmpl.ExecuteTemplate(os.Stdout, "main", nil) if err != nil { panic(err) } // 出力 // *** ヘッダー *** // *** メイン *** // *** フッター ***
テンプレートを保存してるファイルはこんな感じ。
// header.template
{{define "header"}}*** ヘッダー ***{{end}}
// main.template
{{define "main"}}
{{template "header"}}
*** メイン ***
{{template "footer"}}
{{end}}
// footer.template
{{define "footer"}}*** フッター ***{{end}}
text/template と html/template
text/template と html/template は同じインタフェースだけど HTML を出力するときはセキュリティ上の問題から html/template を使うように書いてある。
To generate HTML output, see package html/template, which has the same interface as this package but automatically secures HTML output against certain attacks.
参考ページ
CloudFormation のスタックテンプレートから Secrets Manager のシークレットを動的に参照するメモ。
CloudFormation のスタックテンプレートから Secrets Manager のシークレットを動的に参照するメモ。
CloudFormation のスタックテンプレートから Secrets Manager のシークレットを動的に参照する
CloudFormation のスタックテンプレートからスタックを作っていると必ず一度は秘密情報の扱いをどうするか? みたいな事態に直面する。 ここでは秘密情報というのは DB のパスワードとか Web サービスのAPI キーみたいな「他人に漏れると金銭的損害を始めとしていろんな損害しかも大きな損害を被りそうなすごく秘匿性の高い情報」とかの意味で使うけど、普通に考えると DB のパスワードとか Web サービスの API キーとかを CloudFormation のスタックテンプレートの中に埋め込むのは明らかにまずいと思う。
そういう秘密情報を CloudFormation のスタックテンプレートに使うときは AWS Systems Manager の SecureString パラメータを使う方法と AWS Secrets Manager のシークレットを使う方法があるけどほとんどのケースは AWS Secrets Manager のシークレットを使う方法で事足りるので大概は AWS Secrets Manager のほうを使ってる。 => 一応、秘密情報はパラメータで渡すこともできるけどスタックを作るたびに指定するのは面倒くさい
そのへんのことを軽くメモしていく。
Secrets Manager のシークレットの登録
CloudFormation スタックテンプレートから参照するシークレットは事前に Secrets Manager に登録しておく。
$ aws secretsmanager create-secret --name=db-root-account --secret-string='{"username":"this-is-username","password":"this-is-password"}'
{
"VersionId": "eaaac565-8481-4e22-8ae1-2e1ba125a233",
"Name": "db-root-account",
"ARN": "<ARN>"
}
このあと CloudFormation スタックテンプレートからバージョンを指定してシークレットを取得していくのでシークレットを更新しておく => VersionId のとこがシークレットを登録したときから変わる
$ aws secretsmanager update-secret --secret-id=db-root-account --secret-string='{"username":"this-is-new-username","password":"this-is-new-password"}'
{
"VersionId": "5606eb1c-2892-4721-9936-324527c366b1",
"Name": "db-root-account",
"ARN": "<ARN>"
}
シークレットのバージョンを指定しないでシークレットを取得すると VersionStages が AWSCURRENT のシークレットを取得する。
VersionId のとこがシークレットを更新したときの出力が一致している。
$ aws secretsmanager get-secret-value --secret-id=db-root-account --version-id=5606eb1c-2892-4721-9936-324527c366b1
{
"Name": "db-root-account",
"VersionId": "5606eb1c-2892-4721-9936-324527c366b1",
"SecretString": "{\"username\":\"this-is-new-username\",\"password\":\"this-is-new-password\"}",
"VersionStages": [
"AWSCURRENT"
],
"CreatedDate": 1593245998.012,
"ARN": "<ARN>"
}
シークレットを更新したときの VersionId を指定してシークレットを取得するとさきほどと同じシークレットを取得する。
$ aws secretsmanager get-secret-value --secret-id=db-root-account --version-id=5606eb1c-2892-4721-9936-324527c366b1
{
"Name": "db-root-account",
"VersionId": "5606eb1c-2892-4721-9936-324527c366b1",
"SecretString": "{\"username\":\"this-is-new-username\",\"password\":\"this-is-new-password\"}",
"VersionStages": [
"AWSCURRENT"
],
"CreatedDate": 1593245998.012,
"ARN": "<ARN>"
}
シークレットを最初に登録したときの VersionId を指定してシークレットを取得すると最初に登録したシークレットを取得する。
$ aws secretsmanager get-secret-value --secret-id=db-root-account --version-id=eaaac565-8481-4e22-8ae1-2e1ba125a233
{
"Name": "db-root-account",
"VersionId": "eaaac565-8481-4e22-8ae1-2e1ba125a233",
"SecretString": "{\"username\":\"this-is-username\",\"password\":\"this-is-password\"}",
"VersionStages": [
"AWSPREVIOUS"
],
"CreatedDate": 1593245628.992,
"ARN": "<ARN>"
}
CloudFormation のスタックテンプレートからシークレットを参照
CloudFormation スタックテンプレートから Secrets Manager に登録しているシークレットを動的に参照していく。作成するリソースはなんでもいいんだけどすぐに作れてお金がかからないセキュリティグループを作成していく。
まずバージョンは指定しないでシークレットを参照していく。 こんな感じのスタックテンプレートを書いて CloudFormation スタックを作成していく。
AWSTemplateFormatVersion: "2010-09-09"
Resources:
HogeSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: dynamic refernces
GroupName: hoge-security-group
SecurityGroupIngress:
- CidrIp: 0.0.0.0/0
IpProtocol: tcp
FromPort: 80
ToPort: 80
Description: '{{resolve:secretsmanager:db-root-account:SecretString:username::}}'
- CidrIp: 0.0.0.0/0
IpProtocol: tcp
FromPort: 443
ToPort: 443
Description: '{{resolve:secretsmanager:db-root-account:SecretString:password::}}'
VpcId: <VPC ID>
CLI でセキュリティグループの定義を見てみると更新したあとのシークレットが取得しているのが分かる。
$ aws ec2 describe-security-groups --group-names=hoge-security-group | jq '.SecurityGroups[].IpPermissions[].IpRanges[].Description' "this-is-new-username" "this-is-new-password"
次はシークレットのバージョンを指定してシークレットを参照していく。
シークレットを最初に登録したときの VersionId の eaaac565-8481-4e22-8ae1-2e1ba125a233 を Description のとこに追加して CloudFormation スタックを作成していく。
AWSTemplateFormatVersion: "2010-09-09"
Resources:
HogeSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: dynamic refernces
GroupName: hoge-security-group
SecurityGroupIngress:
- CidrIp: 0.0.0.0/0
IpProtocol: tcp
FromPort: 80
ToPort: 80
Description: '{{resolve:secretsmanager:db-root-account:SecretString:username::eaaac565-8481-4e22-8ae1-2e1ba125a233}}'
- CidrIp: 0.0.0.0/0
IpProtocol: tcp
FromPort: 443
ToPort: 443
Description: '{{resolve:secretsmanager:db-root-account:SecretString:password::eaaac565-8481-4e22-8ae1-2e1ba125a233}}'
VpcId: <VPC ID>
CLI でセキュリティグループの定義を見てみると最初に登録したシークレットが取得しているのが分かる。
$ aws ec2 describe-security-groups --group-names=hoge-security-group | jq '.SecurityGroups[].IpPermissions[].IpRanges[].Description' "this-is-username" "this-is-password"
CloudFormation スタックテンプレートからはこんな感じで Secrets Manager に登録しているシークレットを取得できる。
気にしておきたいこと
シークレットのリファレンスパターン
CloudFormation スタックテンプレートから Secrets Manager に登録しているシークレットを参照するときは {{resolve:secretsmanager:secret-id:secret-string:json-key:version-stage:version-id}} の形式で参照していく。
resolve:secretsmanager の部分は固定で、それ以外の部分はそれぞれの意味と使い方を書いていく。
secret-id
secret-id のとこは Secrets Manager に登録しているシークレットの ID を指定する。シークレットの完全な ARN を指定して別の AWS アカウントのシークレットを参照することもできる。
さきほどの例は db-root-account を指定した。
secret-string
SecretString 固定。
json-key
値を取得するシークレットのキー名を指定する。 CloudFormation は json-key を省略するとシークレットテキスト全体を取得する。
さきほどの例は username と password を指定してシークレットのユーザー名とパスワードがそれぞれセキュリティグループの ingress ルールの Description に埋め込んだやつ。
もしさきほどの例で json-key を省略すると {"username":"this-is-new-username","password":"this-is-new-password"} がセキュリティグループの ingress ルールの Description に埋め込む感じ。
version-stage
version-stage を指定して取得するシークレットのバージョンを指定できる。
version-stage は AWSCURRENT とか AWSPREVIOUS とかがある。
version-stage と verson-id はどちらか1つしか指定できないので version-stage を指定するときは version-id は指定できず、version-stage も version-id も指定しないときは AWSCURRENT の version-stage を指定したのと同じになる。
さきほどの1つめの CloudFormation スタックテンプレートは version-stage も version-id も指定しないので AWSCURRENT の version-stage を指定したのと同じつまり更新後のシークレット this-is-new-username と this-is-new-password を取得している。
version-id
version-id を指定して取得するシークレットのバージョンを指定できる。
version-stage と verson-id はどちらか1つしか指定できないので version-stage を指定するときは version-id は指定できず、version-stage も version-id も指定しないときは AWSCURRENT の version-stage を指定したのと同じになる。
さきほどの2つめの CloudFormation スタックテンプレートは最初にシークレットを登録したときの version-id を指定しているので最初に登録したときのシークレット this-is-username と this-is-password を取得している。
必要なアクセス許可
Secrets Manager に格納されているシークレットを取得するには取得するシークレットに対して GetSecretValue を呼び出すためのアクセス権を持っている必要がある。
動的参照の制限
CloudFormation テンプレートスタックから Secrets Manager に登録しているシークレットを取得するとき固有の制限ではなくて動的参照に共通している制限だけどいくつか制限があるので書いておく。
- スタックテンプレートは動的参照を最大で60個までしか含めない
AWS::IncludeとかAWS::Serverlessなどのトランスフォームの場合、AWS CloudFormation はトランスフォームを呼び出す前には動的な参照を解決せず、動的参照のリテラル文字列をトランスフォームに渡す- カスタムリソースは Secrets Manager に登録しているシークレットは動的参照できない
- CloudFormation は最終値としてバックスラッシュを含む動的な参照は解決できない
参考ページ
CDK で EC2 のユーザーデータを構築する方法。
EC2 はインスタンスを起動するときにユーザーデータをインスタンスに渡してツールをセットアップしたりスクリプトを実行できるけど、CDK で EC2 のユーザーデータを構築する方法をメモしておく。
CDK で EC2 のユーザーデータを構築する
CDK で EC2 のユーザーデータを構築する方法はいくつかあるのでそれぞれを書いていく。
CDK で EC2 のユーザーデータを構築する方法はいくつかあるけど、先に結論を書いちゃうと今のとこは UserData.addCommands() と fs モジュールを組み合わせる方法がベストプラクティスのような気がしてる。
UserData.addCommands()
ユーザーデータを UserData.addCommands() で追加していく。
UserData.addCommands()で追加したユーザーデータは EC2 インスタンスの /var/lib/cloud/instances/<instance-id>/user-data.txt にコピーされて EC2 インスタンスの起動時に実行される。
この方法は簡単だけどユーザーデータでやることが増えていくと UserData.addCommands() のとこをたくさん書くことになるのが少し面倒くさい。
import * as cdk from '@aws-cdk/core' import * as ec2 from '@aws-cdk/aws-ec2' const userData = ec2.UserData.forLinux({shebang: '#!/bin/bash'}) userData.addCommands( 'echo userData doing!', 'echo userData done!', )
Asset construct
aws-s3-assets の Asset construct を使うとローカルのファイルをそのままユーザーデータとして構築して EC2 インスタンスの起動時に実行する。
import * as cdk from '@aws-cdk/core' import * as ec2 from '@aws-cdk/aws-ec2' import {Asset} from '@aws-cdk/aws-s3-assets' import * as path from 'path' // ユーザーデータを S3 にアップロードする const asset = new Asset(this, 'userdata-asset', { path: path.join(__dirname, 'assets', 'userdata.sh') }) // なんか EC2 インスタンスを作る const instance = new ec2.Instance(this, 'ec2', { // 省略 }) // ユーザーデータを S3 からダウンロードする asset.grantRead(instance.role) const localPath = instance.userData.addS3DownloadCommand({ bucket: asset.bucket, bucketKey: asset.s3ObjectKey, }) // S3 からダウンロードしたユーザーデータを実行する instance.userData.addExecuteFileCommand({ filePath: localPath, })
CDK アプリはこんな感じのディレクトリ構成を想定してる。
lib/userdata-stack.ts がスタック定義で lib/assets/userdata.sh がユーザーデータ。
├── bin │ └── practice_of_cdk.ts ├── cdk.json ├── cdk.out ├── lib │ ├── assets │ │ └── userdata.sh │ └── userdata-stack.ts │ (省略)
この方法はユーザーデータのシェルスクリプトを普通にエディターとかでいじれるのが楽。
#!/bin/bash echo userData doing! echo userData end!
ただ、この方法は aws-s3-assets が CDK 1.46.0 時点では experimental であるため将来的に破壊的な変更が入る可能性がある。
UserData.addCommands() + fs モジュール
今のところは UserData.addCommands() と fs モジュールを組み合わせる方法がベストプラクティスのような気がしてる。
この方法はユーザーデータのシェルスクリプトを普通にエディターとかでいじれるのが楽なのと experimental な API を使ってないので CDK のバージョンを上げるときに破壊的な変更が入ることを気にしなくていい。
import * as cdk from '@aws-cdk/core' import * as ec2 from '@aws-cdk/aws-ec2' import * as path from 'path' const userData = ec2.UserData.forLinux({shebang: '#!/bin/bash'}) // ローカルのユーザーデータのファイルを読み込む const script = fs.readFileSync( path.join(__dirname, 'assets', 'userdata.sh'), {encoding: 'utf8'}) // 読み込んだユーザーデータを改行コードで split して userData.addCommands() に追加する userData.addCommands(...script.split('\n'))
ユーザーデータの実行ログとか
ユーザーデータの実行ログは /var/log/cloud-init-output.log に出力する。
ユーザーデータがやることが増えていくと EC2 インスタンスが起動してもユーザーデータの実行がなかなか終わらないとか増えてくると思うので tail -f /var/log/cloud-init-output.log みたいなコマンドでユーザーデータのログが流れていくのを見たりしてる。
参考ページ
Travis CI で環境変数を暗号化して使う方法。
Travis CI で環境変数を暗号化して .travis.yml に保存してアプリから使う方法をメモしておく。
Travis CI で環境変数を暗号化して使う方法
環境とか前提条件
Travis CI は travis-ci.comを使ってる。
環境変数の暗号化に使う travis コマンドのバージョン。
$ travis --version 1.9.1
環境変数の暗号化
環境変数の暗号化は travis コマンドを使う。 Mac は Homebrew でインストールするのが楽だと思う。
$ brew install travis
環境変数は travis login コマンドで Travis CI にログインしてから暗号化していく。
Travis CI は travis-ci.comを使うので travis login コマンドは --com オプションか --pro オプションを指定していく。
$ travis login --com
カレントディレクトリを Git リポジトリに移動してから travis encrypt コマンドで環境変数を暗号化していく。
Travis CI は travis-ci.comを使うので travis encrypt コマンドは --com オプションか --pro オプションを指定していく。
暗号化した環境変数は travis encrypt コマンドの出力の secure: に続いて出力するので .travis.yml にコピペする。
$ cd /path/to/your/git/repo $ travis encrypt --com MY_SECRET_ENV=super_secret Please add the following to your .travis.yml file: secure: "dIEvchZ14clAFpaxtTwQrKSy3ueNgQSUGilGQRKMmV8tWJq3iVoZwQxr5uggrQdyL74MuFOweELyuMXcw4bGX5W/pBecZ7weacrEw2Phaf/M81sjv4dmhT86XNsqzR3ZjhR2DzeyFMAbmyTWbV3iCJ7PVj6KIodPku1bHKZuTDhfgIO3/zz9GYSSlt6xyE+X+0R9853vN4hw2Xls64obHUv+UL5/uxWK3scvTM1LnSddzbX+oLCbxN6kNJV9YKYN36M22WXMLqqtPPr5L9ogNPrGSr6iMsfWuvgyNzP4gv4tUqEP6aTiLFM5PVf36BVZWjkkAnlKeptFkzNVeA9uSLykbTn3ju8ESq/lXVEBbhv/Ig2etEP2IuA0+7nOA43fn++cDn7iJ4TYKZszXtoHp2wG/OoDwfF/h58RS6JiosfBNczetoEokM82tXBrXf3OKoTVxoKmac+i65FFMgDNU4KtIPb58fPw9CVpOIWNPjzXtfbJ78YrZhjl1gyMHLQKK3hHhB7M4l4v8CVHeqe5cAxCK0oQs5TW5dEP+dDbr/pmbwqImGwhM1ClENCpFFPegFVHILjtpV+s5nvkFepd/v5WzBIUhWigaho43U6xGUky2fa5dwicCaegU5PwMOBAZtYAPzQGCnXAnquqD2dVIucghFGvNudrDaYNHTEZOiY=" Pro Tip: You can add it automatically by running with --add.
暗号化した環境変数はこんな感じで .travis.yml に入れる。
env: global: - secure: dIEvchZ14clAFpaxtTwQrKSy3ueNgQSUGilGQRKMmV8tWJq3iVoZwQxr5uggrQdyL74MuFOweELyuMXcw4bGX5W/pBecZ7weacrEw2Phaf/M81sjv4dmhT86XNsqzR3ZjhR2DzeyFMAbmyTWbV3iCJ7PVj6KIodPku1bHKZuTDhfgIO3/zz9GYSSlt6xyE+X+0R9853vN4hw2Xls64obHUv+UL5/uxWK3scvTM1LnSddzbX+oLCbxN6kNJV9YKYN36M22WXMLqqtPPr5L9ogNPrGSr6iMsfWuvgyNzP4gv4tUqEP6aTiLFM5PVf36BVZWjkkAnlKeptFkzNVeA9uSLykbTn3ju8ESq/lXVEBbhv/Ig2etEP2IuA0+7nOA43fn++cDn7iJ4TYKZszXtoHp2wG/OoDwfF/h58RS6JiosfBNczetoEokM82tXBrXf3OKoTVxoKmac+i65FFMgDNU4KtIPb58fPw9CVpOIWNPjzXtfbJ78YrZhjl1gyMHLQKK3hHhB7M4l4v8CVHeqe5cAxCK0oQs5TW5dEP+dDbr/pmbwqImGwhM1ClENCpFFPegFVHILjtpV+s5nvkFepd/v5WzBIUhWigaho43U6xGUky2fa5dwicCaegU5PwMOBAZtYAPzQGCnXAnquqD2dVIucghFGvNudrDaYNHTEZOiY=
travis encrypt コマンドの出力を .travis.yml にコピペするのは面倒くさいけど travis encrypt コマンドを --add オプションを指定して実行すると暗号化した環境変数を .travis.yml に追加するかの確認のプロンプトが表示する。
y を入力すると暗号化した環境変数が .travis.yml に反映する。楽。
$ travis encrypt --com MY_SECRET_ENV=super_secret --add
Overwrite the config file /path/to/your/git/repo/.travis.yml with the content below?
This reformats the existing file.
---
env:
global:
secure: hMvpI0fq/FtqpevJU1wOu72votNKw+UeVwoWjqfBef8e//J4GrzGaK7qw8TcU+qhg2DWSXOjDhxgQO419tSOnsMj0YrmRX2R07girRnAWzJn19zgklYCUC9l3vX2qYnq+iFq22Gg94w/R9O5V7HfKbcg9weqpTyv8rX4yrLBRs48YKVWZzEWL6Ui1JKL0LGdThbeekSPN5kfs900rTR5jMPF9ILtoZAT9nSmcYplXP0jXfk4w7wrHszP0p+J1lhqYi+IoAEbb4Vh0WlzigLrFNTOjKiBGxer8JBeXut7x0DdWuGfM1ujVwbeG9SIxNr0CRuYBUl/NeDqfSSq5JJcUd3T8I/CuWROBgTkb1lG9ehr2+kuKC8hbYVbmrnv9Vztjmrk/21XVsHWMIdNj+ihkuUWTggErJ+uk3knqjv94noW9Pni2TWQI+NdrKZhwvCL2+lZpnyuTX5v0etT85aaGq1cDfipI6aB6bPeW1gitG6s2jPlA8AG7qGMOwZbh2Kn0TtIBiwl/CJWCAfLAzqZ7awWDaRg28Jb6R069ON3ZVAXw4eKoW37FNhLZJp2nDHtE+vWBoNkJRt1uPliVE1p2xn9OosQ2tWGtu/yaJSSZOCOgWiBWcsH/jhgRwI1ybOMwsAfygHmsniRPel2oDJ2pi7WWvCJu17E0UKy5Bnzs30=
(y/N)
カレントディレクトリを Git リポジトリに移動してから travis encrypt コマンドで環境変数を暗号化したけど、実は travis encrypt --repo <SLUG> みたいに --repo オプションで Github のリポジトリを指定するとカレントディレクトリがどこにいても環境変数を暗号化することができる。
ただ --add オプションが効かなくなるので暗号化した環境変数を .travis.yml にコピペするのが面倒くさいので、自分はカレントディレクトリを Git リポジトリに移動してから travis encrypt --add してる。
暗号化した環境変数の Travis CI ログへの出力
暗号化した環境変数は [secure] みたいにマスクして Travis CI のログに出力する。
Setting environment variables from .travis.yml $ export MY_SECRET_ENV=[secure]
参考ページ
AWS Lambda と pixela4go を使って Github リポジトリのクローン数の草を Pixela に生やすメモ。
※この記事は AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすメモ を pixela4go を使うように書き直したものです。
Github は Web UI や API を使ってリポジトリのクローン数を取得することができるのだが、どちらの方法を使っても過去2週間分のクローン数しか見られない。そこで、AWS Lambda を使って定期的に Github のクローン数を取得して Pixela に記録することにした。Pixela は操作が簡単な上に草を生やすことができるのでビジュアル面でも Github のクローン数を記録するという用途にぴったりだ。
実際に pixela-client-go のクローン数を Pixela に記録してみるとこんな感じになる。
AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすまでにしたことをメモしておく。
はじめに
使うもの
前提条件
もし AWS のアカウントや Github のアカウントがないとか API トークンがないなら事前に取得しておく。 このあたりの情報は公式サイトはもちろんネット上にたくさんあるので困ることはないと思う。
やること
- Pixela アカウントとグラフを作成
- Lambda 関数の作成
- トリガーを追加
- 関数パッケージの作成
- 関数パッケージのアップロード
- 環境変数の設定
- Lambda 関数の動作確認
Pixela アカウントとグラフを作成
Github のクローン数を Pixela に記録するために Pixela アカウントの作成と Pixela グラフを作成する。 公式ブログを見ながら作っていくと迷うことなく作れると思う。
Lambda 関数の作成
関数の作成
Github のクローン数を取得して Pixela に記録する関数を作成していく。
AWS コンソール を表示して Lambda > 関数 > 関数の作成 ボタンを押す。

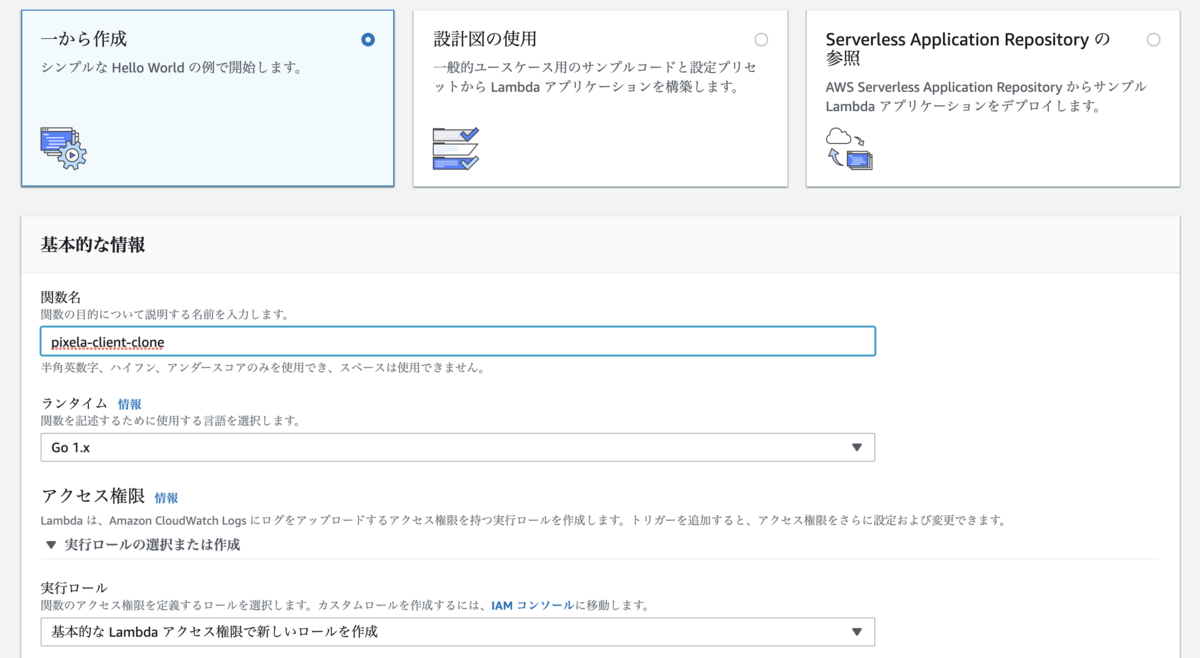
一から作成 を選んで関数名を入力する。
ランタイムは Go 1.x を選んで実行ロールは 基本的な Lambda アクセス権限で新しいロールを作成 を選ぶ。
トリガーを追加
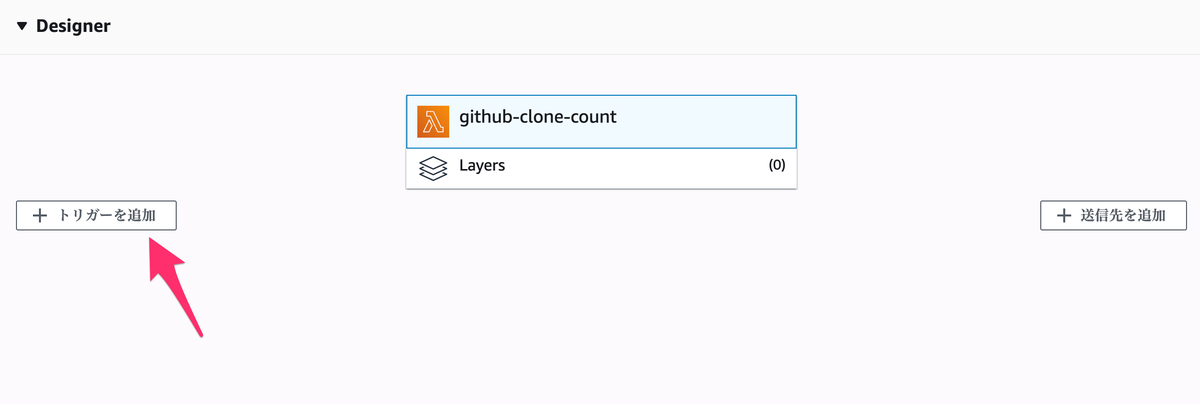
作成した関数を定期的に動かすためにトリガーを設定していく。
Designer の トリガーを追加 を押してトリガーの設定画面を表示する。
トリガーの設定画面は以下のように設定する。
- トリガーの選択は
CloudWatch Eventsを選択 - ルールは
新規ルールの作成を選択 - ルール名は
0100-utc-everydayを入力 - ルールタイプは
スケジュール式を選択 - スケジュール式は
cron(0 1 * * ? *)を入力
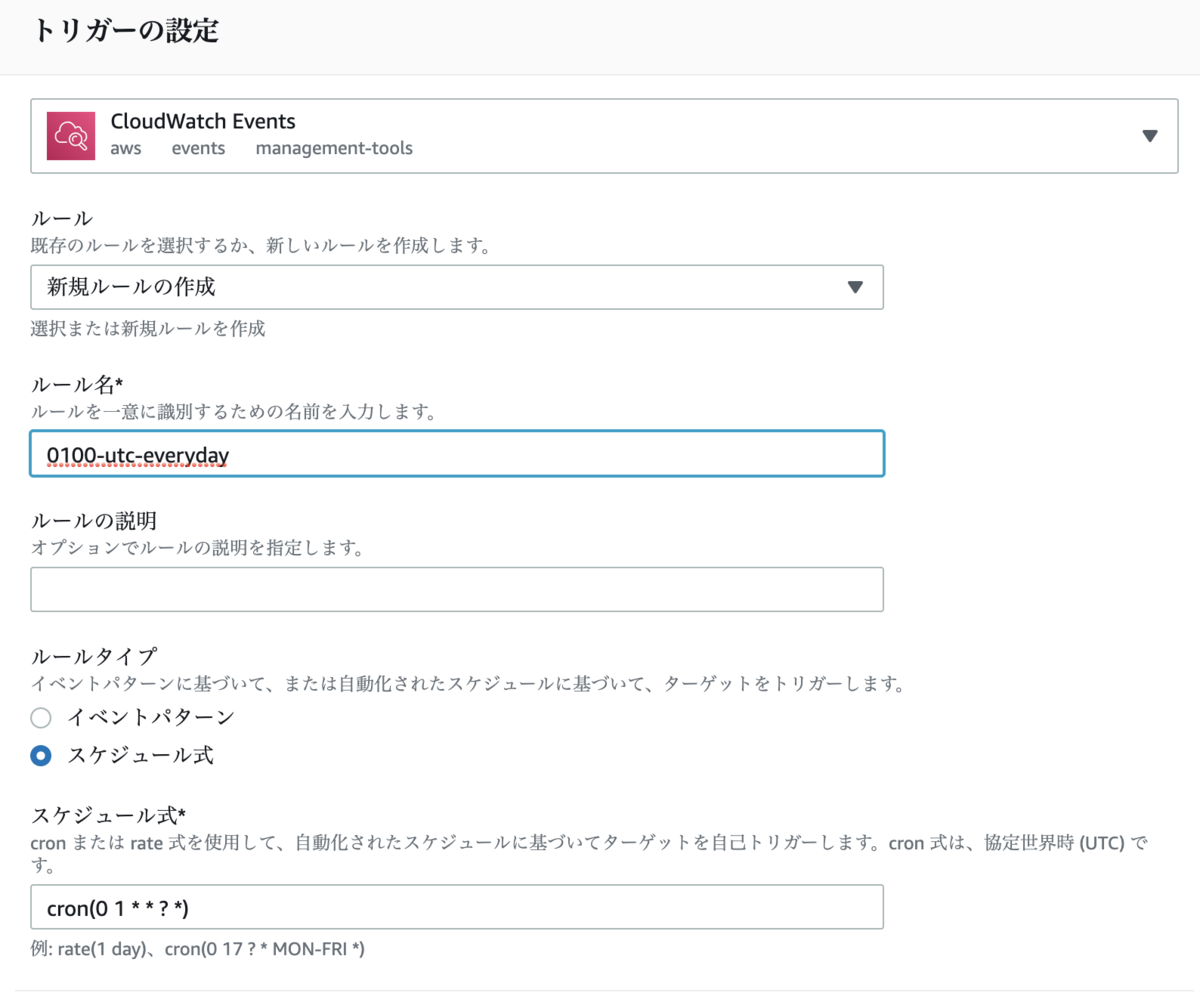
トリガーの有効化 にチェックを付けて 追加 ボタンを押す。

トリガーの設定はこれで完了。この設定をしておくと Lambda 関数が毎日1時 (UTC) に自動的に実行するようになる。
関数パッケージの作成
Lambda で動かす関数パッケージを作っていく。
以下のコードを main.go というファイル名で保存する。
package main import ( "context" "errors" "os" "strconv" "time" "github.com/aws/aws-lambda-go/lambda" "github.com/ebc-2in2crc/pixela4go" "github.com/google/go-github/github" "golang.org/x/oauth2" ) const timeFormat = "20060102" type MyEvent struct { Time time.Time `json:"time"` } var ( githubToken = os.Getenv("GITHUB_TOKEN") githubUser = os.Getenv("GITHUB_USER") githubRepo = os.Getenv("GITHUB_REPO") pixelaToken = os.Getenv("PIXELA_USER_TOKEN") userName = os.Getenv("PIXELA_USER_NAME") graphID = os.Getenv("PIXELA_GRAPH_ID") ) func main() { lambda.Start(HandleRequest) } func HandleRequest(event MyEvent) (string, error) { yesterday := event.Time.Truncate(time.Hour * 24).Add(-time.Hour * 24) cloneCount, err := retrieveCloneCount(yesterday) if err != nil { return "failed to retrieve clone count", err } if err := registerCloneCount(yesterday, cloneCount); err != nil { return "failed to register clone count", err } return "success", nil } func retrieveCloneCount(t time.Time) (int, error) { client := newGithubClient(githubToken) clones, resp, err := client.Repositories.ListTrafficClones( context.Background(), githubUser, githubRepo, &github.TrafficBreakdownOptions{Per: "day"}, ) if err != nil { return 0, err } _ = resp.Body.Close() d := t.Format(timeFormat) for _, c := range clones.Clones { if c.GetTimestamp().Format(timeFormat) == d { return c.GetCount(), nil } } return 0, nil } func newGithubClient(token string) *github.Client { oauthCli := oauth2.NewClient(context.Background(), oauth2.StaticTokenSource(&oauth2.Token{ AccessToken: token, })) return github.NewClient(oauthCli) } func registerCloneCount(date time.Time, cloneCount int) error { client := pixela.New(userName, pixelaToken) pci := &pixela.PixelCreateInput{ GraphID: pixela.String(graphID), Date: pixela.String(date.Format(timeFormat)), Quantity: pixela.String(strconv.Itoa(cloneCount)), } result, err := client.Pixel().Create(pci) if err != nil { return err } if result.IsSuccess == false { return errors.New(result.Message) } return nil }
AWS Lambda にアップロードする zip ファイルを作成する。
$ go build -o hello main.go && zip hello.zip hello adding: hello (deflated 53%)
Mac や Windows でコンパイルするときは GOOS=linux を付けて Linux 向けにクロスコンパイルする。
$ GOOS=linux go build -o hello main.go && zip hello.zip hello adding: hello (deflated 53%)
main.go がやっていること
main.go はざっくり書くと「プログラムの実行日付の前日の Github リポジトリのクローン数を取得」して「プログラム実行日付の前日の (PIxela の) Pixel に記録」している。
当日のクローン数を当日の Pixel に記録したいときは yesterday := event.Time.Truncate(time.Hour * 24).Add(-time.Hour * 24) のあたりを適当にいじるとよい。
関数パッケージのアップロード
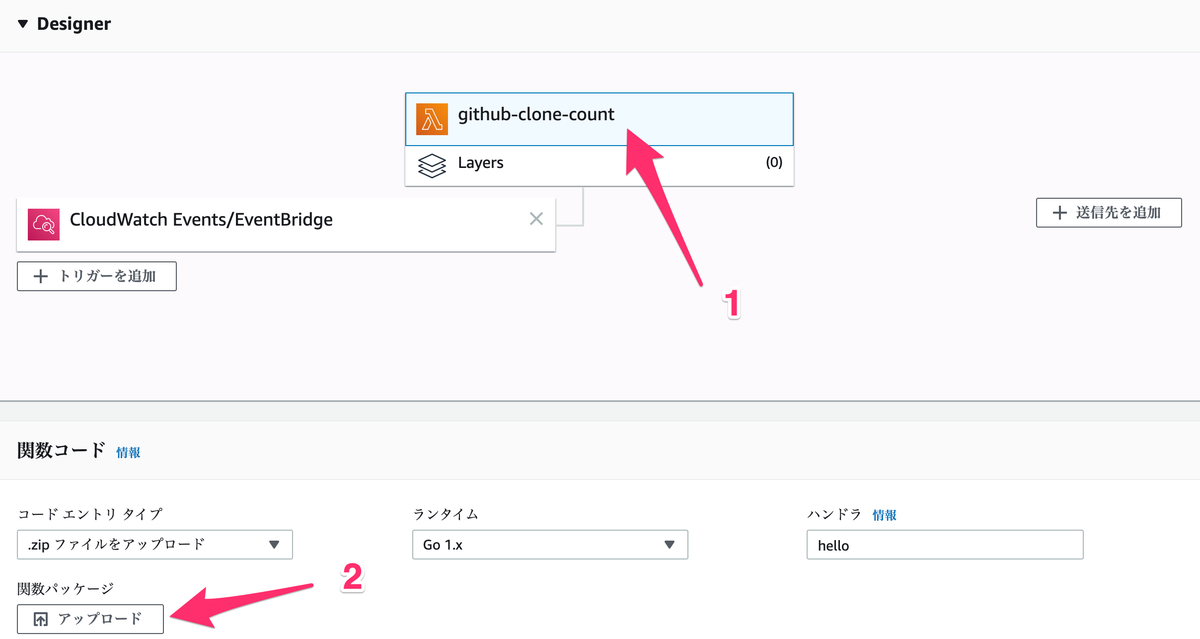
作成した zip ファイルを AWS にアップロードしていく。
コードエントリタイプは .zip ファイルをアップロード を選択して アップロード ボタンを押してさきほど作成した zip ファイルを AWS にアップロードする。
環境変数の設定
関数パッケージが使う環境変数を アップロード ボタンの下の 環境変数 に設定していく。
API トークンなど重要な情報を含んでいるので実際は暗号化するほうがよい。
| 環境変数名 | 設定する値 |
|---|---|
| GITHUB_TOKEN | Github の API トークン |
| GITHUB_USER | Github のユーザー名 |
| GITHUB_REPO | クローン数の草を生やしたいリポジトリ名 |
| PIXELA_USER_TOKEN | Pixela の API トークン |
| PIXELA_USER_NAME | Pixela のユーザー名 |
| PIXELA_GRAPH_ID | クローン数の草を生やす先のグラフの名前 |
これで Lambda 関数の作成は完了。 続いて Lambda 関数がちゃんと動くか確認していく。
Lambda 関数の動作確認
関数パッケージと環境変数が正しく設定されていて Lambda 関数がちゃんと動くかどうかを確認していく。
画面の上のほうにある テストイベントの設定 を押して テストイベントの設定 画面を表示する。

テストイベントの設定 画面は以下のように設定する。
新しいテストイベントの作成を選択- イベントテンプレートは
Hello Worldを選択 - イベント名は
testを入力
イベントの JSON は以下を設定する。
2020-06-04 のところはテストをしたい日付、たとえば Github リポジトリがクローンされたことが分かっている日、あるいは Github リポジトリがクローンされなかったことが分かっている日などを入力する。
{ "time": "2020-06-04T01:00:00Z" }
入力し終わったら 保存 ボタンを押してテストイベントを保存する。
次は作成したテストイベントを使って Lambda 関数の実際の動きを確認していく。
画面の上のほうにある テスト ボタンを押してテストイベント test を使って Lambda 関数を動かす。
実行結果: 成功 が表示されれば Lambda 関数は問題なく動いている。

以上。