注意: この記事の中で利用している pixela-client-go はアクティブな開発は止まっています。
pixela-client-go の後継ライブラリの pixela4go を利用する記事 AWS Lambda と pixela4go を使って Github リポジトリのクローン数の草を Pixela に生やすメモ。を参照してください。
AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすメモ。
Github は Web UI や API を使ってリポジトリのクローン数を取得することができるのだが、どちらの方法を使っても過去2週間分のクローン数しか見られない。そこで、AWS Lambda を使って定期的に Github のクローン数を取得して Pixela に記録することにした。Pixela は操作が簡単な上に草を生やすことができるのでビジュアル面でも Github のクローン数を記録するという用途にぴったりだ。
実際に pixela-client-go のクローン数を Pixela に記録してみるとこんな感じになる。
AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすまでにしたことをメモしておく。
はじめに
使うもの
前提条件
もし AWS のアカウントや Github のアカウントがないとか API トークンがないなら事前に取得しておく。
このあたりの情報は公式サイトはもちろんネット上にたくさんあるので困ることはないと思う。
やること
- Pixela アカウントとグラフを作成
- Lambda 関数の作成
- トリガーを追加
- 関数パッケージの作成
- 関数パッケージのアップロード
- 環境変数の設定
- Lambda 関数の動作確認
Pixela アカウントとグラフを作成
Github のクローン数を Pixela に記録するために Pixela アカウントの作成と Pixela グラフを作成する。
公式ブログを見ながら作っていくと迷うことなく作れると思う。
blog.a-know.me
Lambda 関数の作成
関数の作成
Github のクローン数を取得して Pixela に記録する関数を作成していく。
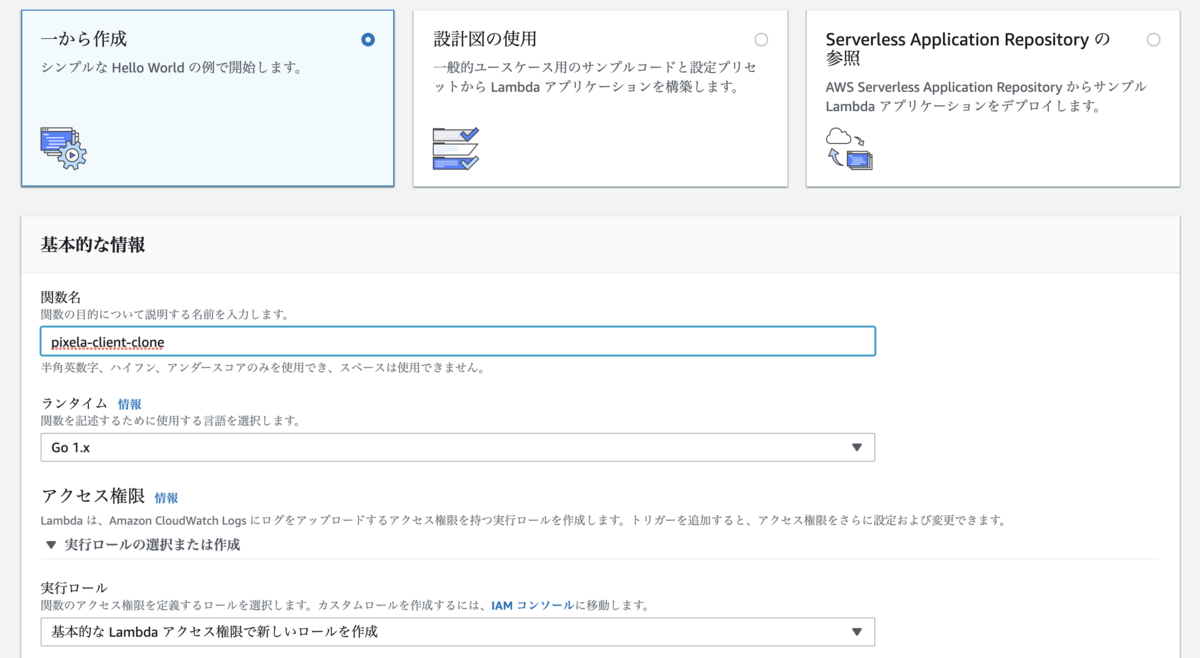
AWS コンソール を表示して Lambda > 関数 > 関数の作成 ボタンを押す。

一から作成 を選んで関数名を入力する。
ランタイムは Go 1.x を選んで実行ロールは 基本的な Lambda アクセス権限で新しいロールを作成 を選ぶ。
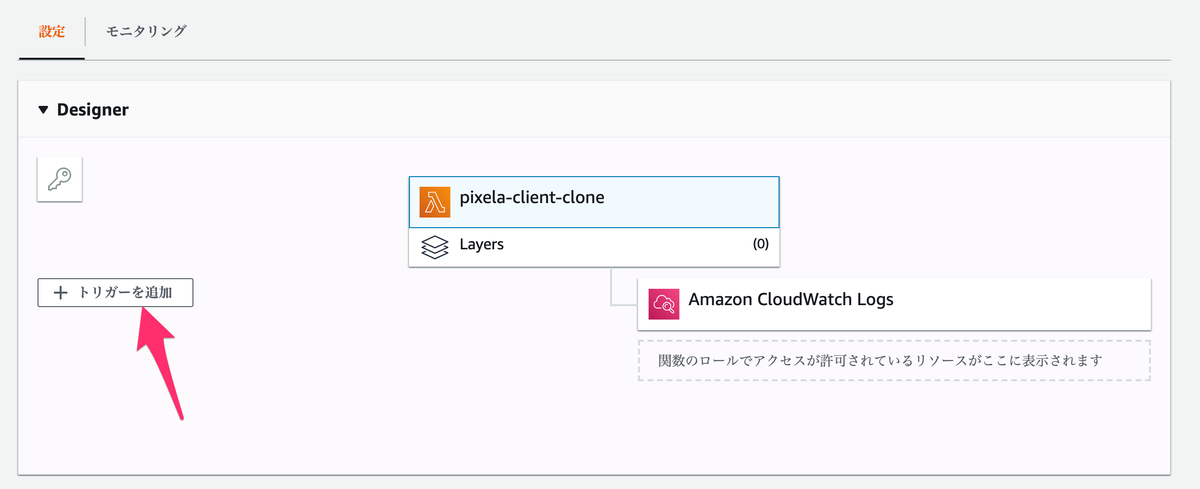
トリガーを追加
作成した関数を定期的に動かすためにトリガーを設定していく。
Designer の トリガーを追加 を押してトリガーの設定画面を表示する。
トリガーの設定画面は以下のように設定する。
- トリガーの選択は
CloudWatch Events を選択
- ルールは
新規ルールの作成 を選択
- ルール名は
0100-utc-everyday を入力
- ルールタイプは
スケジュール式 を選択
- スケジュール式は
cron(0 1 * * ? *) を入力
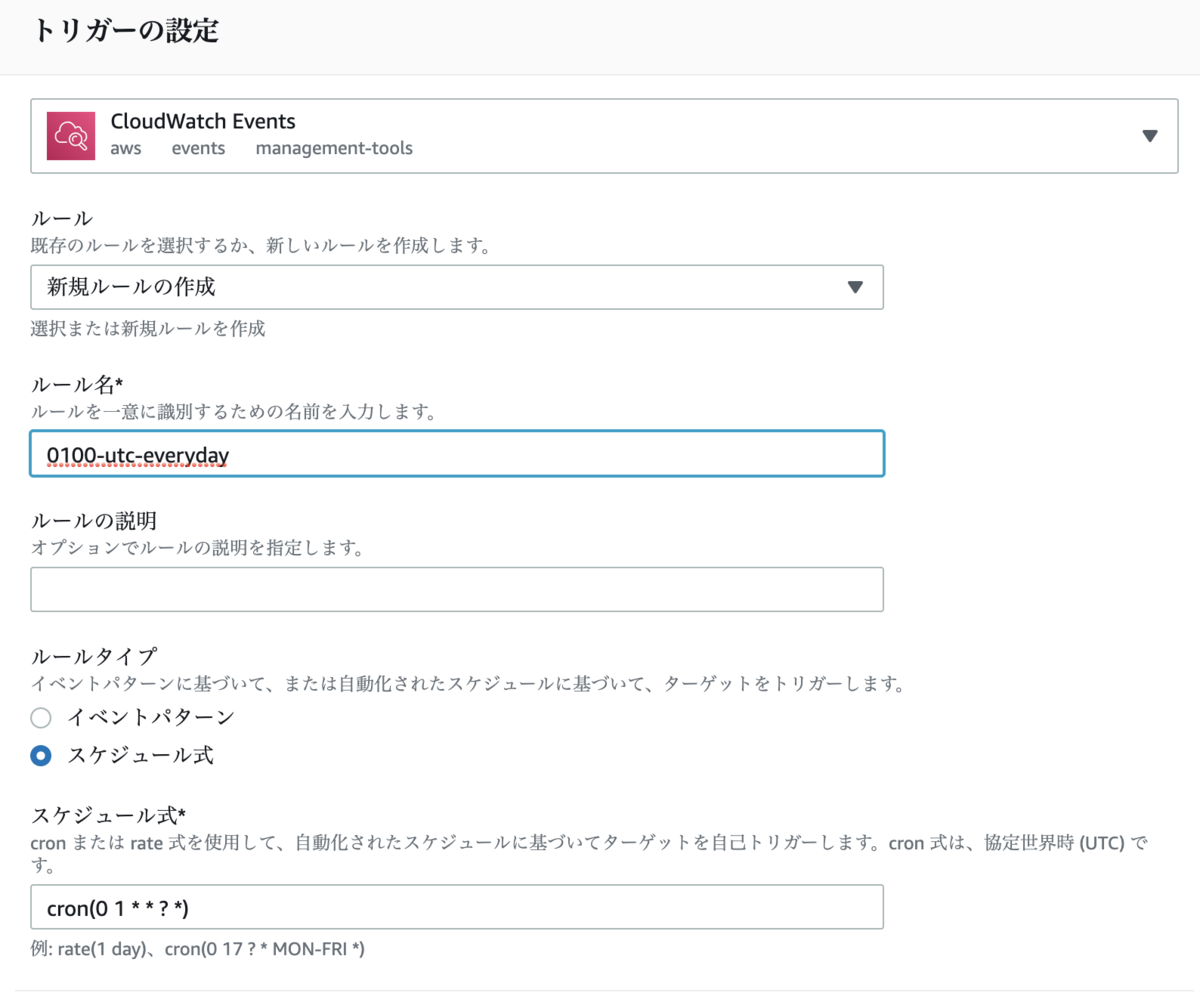
トリガーの有効化 にチェックを付けて 追加 ボタンを押す。

トリガーの設定はこれで完了。この設定をしておくと Lambda 関数が毎日1時 (UTC) に自動的に実行するようになる。
関数パッケージの作成
Lambda で動かす関数パッケージを作っていく。
以下のコードを main.go というファイル名で保存する。
package main
import (
"context"
"errors"
"os"
"strconv"
"time"
"github.com/aws/aws-lambda-go/lambda"
"github.com/ebc-2in2crc/pixela-client-go"
"github.com/google/go-github/github"
"golang.org/x/oauth2"
)
type MyEvent struct {
Time time.Time `json:"time"`
}
const timeFormat = "20060102"
var (
githubToken = os.Getenv("GITHUB_TOKEN")
githubUser = os.Getenv("GITHUB_USER")
githubRepo = os.Getenv("GITHUB_REPO")
pixelaToken = os.Getenv("PIXELA_USER_TOKEN")
userName = os.Getenv("PIXELA_USER_NAME")
graphID = os.Getenv("PIXELA_GRAPH_ID")
)
func main() {
lambda.Start(HandleRequest)
}
func HandleRequest(event MyEvent) (string, error) {
yesterday := event.Time.Truncate(time.Hour * 24).Add(-time.Hour * 24)
cloneCount, err := retrieveCloneCount(yesterday)
if err != nil {
return "failed to retrieve clone count", err
}
if err := registerCloneCount(yesterday, cloneCount); err != nil {
return "failed to register clone count", err
}
return "success", nil
}
func retrieveCloneCount(t time.Time) (int, error) {
client := newGithubClient(githubToken)
clones, resp, err := client.Repositories.ListTrafficClones(
context.Background(),
githubUser,
githubRepo,
&github.TrafficBreakdownOptions{Per: "day"},
)
if err != nil {
return 0, err
}
_ = resp.Body.Close()
d := t.Format(timeFormat)
for _, c := range clones.Clones {
if c.GetTimestamp().Format(timeFormat) == d {
return c.GetCount(), nil
}
}
return 0, nil
}
func newGithubClient(token string) *github.Client {
oauthCli := oauth2.NewClient(context.Background(), oauth2.StaticTokenSource(&oauth2.Token{
AccessToken: token,
}))
return github.NewClient(oauthCli)
}
func registerCloneCount(date time.Time, cloneCount int) error {
client := pixela.NewClient(userName, pixelaToken)
pixel := client.Pixel(graphID)
result, err := pixel.Create(date.Format(timeFormat), strconv.Itoa(cloneCount), "")
if err != nil {
return err
}
if result.IsSuccess == false {
return errors.New(result.Message)
}
return nil
}
AWS Lambda にアップロードする zip ファイルを作成する。
$ go build -o hello main.go && zip hello.zip hello
adding: hello (deflated 53%)
Mac や Windows でコンパイルするときは GOOS=linux を付けて Linux 向けにクロスコンパイルする。
$ GOOS=linux go build -o hello main.go && zip hello.zip hello
adding: hello (deflated 53%)
main.go がやっていること
ざっくり書くと「プログラムの実行日付の前日の Github リポジトリのクローン数を取得」して「プログラム実行日付の前日の (PIxela の) Pixel に記録」している。
当日のクローン数を当日の Pixel に記録したいときは yesterday := event.Time.Truncate(time.Hour * 24).Add(-time.Hour * 24) のあたりを適当にいじるとよい。
関数パッケージのアップロード
作成した zip ファイルを AWS にアップロードしていく。
コードエントリタイプは .zip ファイルをアップロード を選択して アップロード ボタンを押してさきほど作成した zip ファイルを AWS にアップロードする。
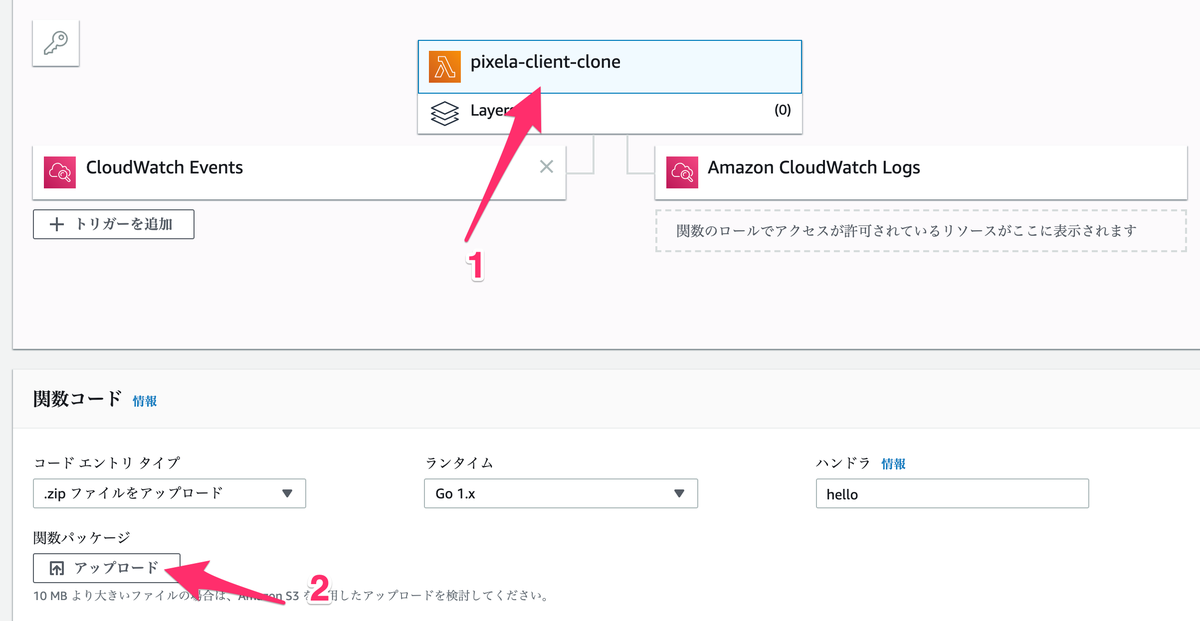
関数パッケージが使う環境変数を アップロード ボタンの下の 環境変数 に設定していく。
API トークンなど重要な情報を含んでいるので実際は暗号化するほうがよい。
これで Lambda 関数の作成は完了。
続いて Lambda 関数がちゃんと動くか確認していく。
Lambda 関数の動作確認
関数パッケージと環境変数が正しく設定されていて Lambda 関数がちゃんと動くかどうかを確認していく。
画面の上のほうにある テストイベントの設定 を押して テストイベントの設定 画面を表示する。

テストイベントの設定 画面は以下のように設定する。
新しいテストイベントの作成 を選択- イベントテンプレートは
Hello World を選択
- イベント名は
test を入力
イベントの JSON は以下を設定する。
2019-08-13 のところはテストをしたい日付、たとえば Github リポジトリがクローンされたことが分かっている日、あるいは Github リポジトリがクローンされなかったことが分かっている日などを入力する。
{
"time": "2019-08-13T01:00:00Z"
}
入力し終わったら 保存 ボタンを押してテストイベントを保存する。
次は作成したテストイベントを使って Lambda 関数の実際の動きを確認していく。
画面の上のほうにある テスト ボタンを押してテストイベント test を使って Lambda 関数を動かす。

実行結果: 成功 が表示されれば Lambda 関数は問題なく動いている。

以上。
参考ページ
blog.a-know.me
developer.github.com
