iTerm2 のカレントのプロファイルは $ITERM_PROFILE で取得できる。
iTerm2 のカレントのプロファイルの取得方法のメモ。
iTerm2 のカレントのプロファイルの取得方法
iTerm2 のカレントのプロファイルは $ITERM_PROFILE で取得できる。
$ echo $ITERM_PROFILE my-favorite-profile
カレントのプロファイルを取得できると何が嬉しいのか
iTerm2 のカレントのプロファイルを取得できると何が嬉しいのかというと用途に応じて iTerm2 のプロファイルを切り替えているのを元のプロファイルに戻したいときなどだ。
iTerm2 のプロファイルは echo "\033]1337;SetProfile=<プロファイル名>\a" で切り替えることができるので、SSH でログインするときにログイン先によってプロファイルを切り替えて、SSH 先からログアウトするときに元のプロファイルに戻すシェルスクリプトは以下のように書くことができる。
#!/bin/sh CUR_PROFILE=$(echo ${ITERM_PROFILE}) echo "\033]1337;SetProfile=$1\a" ssh "$@" echo "\033]1337;SetProfile=${CUR_PROFILE}\a"
普段から iTerm2 の Default プロファイルを使っているとき
普段から iTerm2 の Default プロファイルを使っているときは元のプロファイルに戻すところは echo "\033]1337;SetProfile=Default\a" みたいに決め打ちでいいと思う。
Redash からダウンロードできる CSV ファイルの改行コードが CRLF だった。
Redash からダウンロードできる CSV ファイルの改行コードが CRLF なんだー、と思ったのでメモ。
書いた動機
Redash はクエリーの結果を CSV ファイルでダウンロードすることができるので CSV ファイルをいろいろ加工したりしてとても便利なのだが、Redash からダウンロードした CSV ファイルの改行コードが CRLF であることに気が付かず軽くハマった。
自分は忘れっぽいので時間がたつとまたハマりそうなので忘れないように書いておく。
Redash からダウンロードすることができる CSV の改行コードは CRLF
ダウンロードするものがないと始まらないので、おそらく日本の Redash ユーザーの7割くらいはお世話になっただろう kakakakakku さんの redash-hands-on の city テーブルからデータを引っ張ってみる。
こんな感じの雑な SQL で引っ張ってきたデータの CSV ファイルをダウンロードする。
select * from city limit 3;
で、おもむろに file コマンドで見てみると改行コードが CRLF であることが分かる。
$ file city.csv city.csv: ASCII text, with CRLF line terminators $ cat city.csv ID,Name,CountryCode,District,Population 1,Kabul,AFG,Kabol,1780000 2,Qandahar,AFG,Qandahar,237500 3,Herat,AFG,Herat,186800
一見したところこのファイルは人畜無害なのだが、そのままだと CLI で軽く困ったりする。 たとえば、次のような単純なコマンドもおそらく意図しているとおりには動かない。
$ cat city.csv | xargs -I{} echo "**{}**" **ID,Name,CountryCode,District,Population **1,Kabul,AFG,Kabol,1780000 **2,Qandahar,AFG,Qandahar,237500 **3,Herat,AFG,Herat,186800
ではどうすればいいかというと、CR をとってしまうのが一番簡単 (たぶん)
$ cat city.csv | tr -d \\r | xargs -I{} echo "**{}**" **ID,Name,CountryCode,District,Population** **1,Kabul,AFG,Kabol,1780000** **2,Qandahar,AFG,Qandahar,237500** **3,Herat,AFG,Herat,186800**
Redash からダウンロードする CSV ファイルの改行コードの設定とか Redash のどこかにありそうなものなんだけど、3分くらい探して見つからなかったので雑に CR を削除することにしたときのメモは以上。
どのアベイラビリティゾーン? のやりとりは AZ ID を使うべき理由。
昨日 (8/23) AWS の東京リージョンで大規模な障害が発生した。
Twitter は結構な騒ぎになっていて、インフラと AWS をやり始めたばかりの自分も Service Health Dashboard と Twitter は結構頻繁にチェックしていたのだが「どうも障害が発生しているアベイラビリティゾーンは apne1-az4 らしい」というツイートを Twitter で見つけた。 apne1-az4 というのは AZ ID というものだということは分かったのだが「ap-northeast-1a みたいなやつとなにが違うのか?」と気になってちょっと調べてみたのをメモしておく。
メモ
とりあえず公式ドキュメント。
公式ドキュメントには以下のように書いてある。
アベイラビリティーゾーンは、リージョンコードとそれに続く文字識別子によって表されます (us-east-1a など)。リソースがリージョンの複数のアベイラビリティーゾーンに分散するように、アベイラビリティーゾーンは各 AWS アカウントの名前に個別にマップされます。たとえば、ご使用の AWS アカウントのアベイラビリティーゾーン us-east-1a は別の AWS アカウントのアベイラビリティーゾーン us-east-1a と同じ場所にはない可能性があります。
ようするにアカウント A の us-east-1a = アカウント B の us-east-1a が成り立つとは限らない、ということだ。
では、アカウント A とアカウント B との間で「障害が発生しているのはどのアベイラビリティゾーンか?」という情報を交換するにはどうすればよいかというと、ここで AZ ID の出番となる。 公式ドキュメントには以下のように書いてある。
アカウント間でアベイラビリティーゾーンを調整するには、アベイラビリティーゾーンの一意で一貫性のある識別子である AZ ID を使用する必要があります。たとえば、use1-az1 は、us-east-1 リージョンの AZ ID で、すべての AWS アカウントで同じ場所になります。
まとめると以下のようになる。
- 単一アカウント内で情報をやりとりするときは us-east-1a のようなのでやり取りしていい。別に AZ ID を使ってもいい
- 複数アカウント間で情報をやりとりするときは use1-az1 のような AZ ID でやりとりする必要がある
さいごに
有名サービスやゲームがバタバタと倒れていくなかうちのサービスはほとんど運営に支障はなかったようで大変幸運だった。
Redash のバックアップとリストアのメモ。
サービスの運営で Redash を使っていて運営メンバーは結構カジュアルにクエリとかいじってもらっているので、バックアップとリストアといった運用上必須なところをどうしているかをメモしておく。
はじめに
Redash は 公式の AMI を使って AWS 上に構築しているのでそれ前提で書く。
とはいっても 公式ドキュメント のバックアップ手順は sudo -u redash pg_dump redash | gzip > backup_filename.gz と書いてあるので、ようは Redash が内部で使っている PostgreSQL のバックアップを取得しておけばよい。
同じように、Redash をリストアするときは PostgresSQL のバックアップを Redash が内部で使っている PostgresSQL に流し込めばよい。
バックアップ
バックアップは以下のようなスクリプトを Docker ホスト (= Redash の AMI の EC2 インスタンス) の cron で動かしていて、gzip 圧縮した PostgreSQL のバックアップファイルは S3 へ保管している。
#!/bin/sh # PostgreSQL のコンテナ ID を取得 CID=$(sudo docker container ls | grep redash_postgres | awk '{print $1}') # PostgreSQL をバックアップ sudo docker container exec ${CID} /bin/bash -c 'pg_dump -U postgres postgres | gzip > /usr/local/redash-backup.gz' # PostgreSQL のバックアップファイルを PostgreSQL コンテナからホスト (EC2) へ持ってくる sudo docker container cp ${CID}:/usr/local/redash-backup.gz redash-backup.gz # S3 へ保管 aws s3 cp redash-backup.gz s3://<バケット名>
リストア
リストアは以下のようなスクリプトを redash-restore.sh redash-backup.gz のように実行して、スクリプトがエラーなく終わればブラウザから Redash に接続して動作を確認する。
リストアの手順自体は難しいところはないけどそれなりにコマンドを打つし自分は絶対間違えるのでスクリプト化している。
#!/bin/sh set -x if [ $# -lt 1 ]; then echo 'usage: redash-restore.sh <backup>' exit 1 fi BACKUP_PATH=$(readlink --canonicalize $1) if [ ! -f ${BACKUP_PATH} ]; then echo "${BACKUP_PATH} not exists." exit 1 fi # Redash 公式 AMI は設定ファイルやボリュームは /opt/redash/ にある DOCKER_COMPOSE_YML=/opt/redash/docker-compose.yml # Redash 絡みのコンテナを一旦止める sudo docker-compose --file ${DOCKER_COMPOSE_YML} down --remove-orphans # PostgreSQL のバックアップを流し込む先の PostgreSQL コンテナを動かす sudo docker container run -d -v /opt/redash/postgres-data:/var/lib/postgresql/data -p 5432:5432 postgres:9.5.6-alpine # PostgreSQL のバックアップファイルをホスト (EC2) から PostgreSQL コンテナへ持っていく CID=$(sudo docker container ls | grep postgres | awk '{print $1}') sudo docker container cp ${BACKUP_PATH} ${CID}:/usr/local/redash-backup.gz # Redash のデータベースを削除 & 再作成 sudo docker container exec ${CID} /bin/bash -c 'psql -c "drop database if exists postgres" -U postgres template1' sudo docker container exec ${CID} /bin/bash -c 'psql -c "create database postgres" -U postgres template1' # バックアップを PostgreSQL へ流し込む sudo docker container exec ${CID} /bin/bash -c 'zcat /usr/local/redash-backup.gz | psql -U postgres -d postgres' # バックアップの流し込みに使った PostgreSQL のコンテナはもう使わないので止める sudo docker container stop ${CID} sudo docker container rm ${CID} # Redash 絡みのコンテナを動かす sudo docker-compose --file ${DOCKER_COMPOSE_YML} up --detach
参考ページ
- https://redash.io/help/open-source/admin-guide/maintenance
- Redash を Backup & Restore する - kakakakakku blog
- Docker上のRedashのバックアップとリストア手順 - Kuchitama Tech Note
まとめ
いまのところは Redash のクエリやダッシュボードのバックアップは PostgreSQL のバックアップで十分に事足りているが、バックアップとは別に Redash 特にクエリの変更履歴は管理したいなーと思っているので、そっちも調べて運用に取り込んでいきたい。
AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすメモ。
注意: この記事の中で利用している pixela-client-go はアクティブな開発は止まっています。 pixela-client-go の後継ライブラリの pixela4go を利用する記事 AWS Lambda と pixela4go を使って Github リポジトリのクローン数の草を Pixela に生やすメモ。を参照してください。
AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすメモ。
Github は Web UI や API を使ってリポジトリのクローン数を取得することができるのだが、どちらの方法を使っても過去2週間分のクローン数しか見られない。そこで、AWS Lambda を使って定期的に Github のクローン数を取得して Pixela に記録することにした。Pixela は操作が簡単な上に草を生やすことができるのでビジュアル面でも Github のクローン数を記録するという用途にぴったりだ。
実際に pixela-client-go のクローン数を Pixela に記録してみるとこんな感じになる。
AWS Lambda を使って Github リポジトリのクローン数の草を Pixela に生やすまでにしたことをメモしておく。
はじめに
使うもの
- AWS Lambda
- Pixela
- pixela-client-go
前提条件
もし AWS のアカウントや Github のアカウントがないとか API トークンがないなら事前に取得しておく。 このあたりの情報は公式サイトはもちろんネット上にたくさんあるので困ることはないと思う。
やること
- Pixela アカウントとグラフを作成
- Lambda 関数の作成
- トリガーを追加
- 関数パッケージの作成
- 関数パッケージのアップロード
- 環境変数の設定
- Lambda 関数の動作確認
Pixela アカウントとグラフを作成
Github のクローン数を Pixela に記録するために Pixela アカウントの作成と Pixela グラフを作成する。 公式ブログを見ながら作っていくと迷うことなく作れると思う。
Lambda 関数の作成
関数の作成
Github のクローン数を取得して Pixela に記録する関数を作成していく。
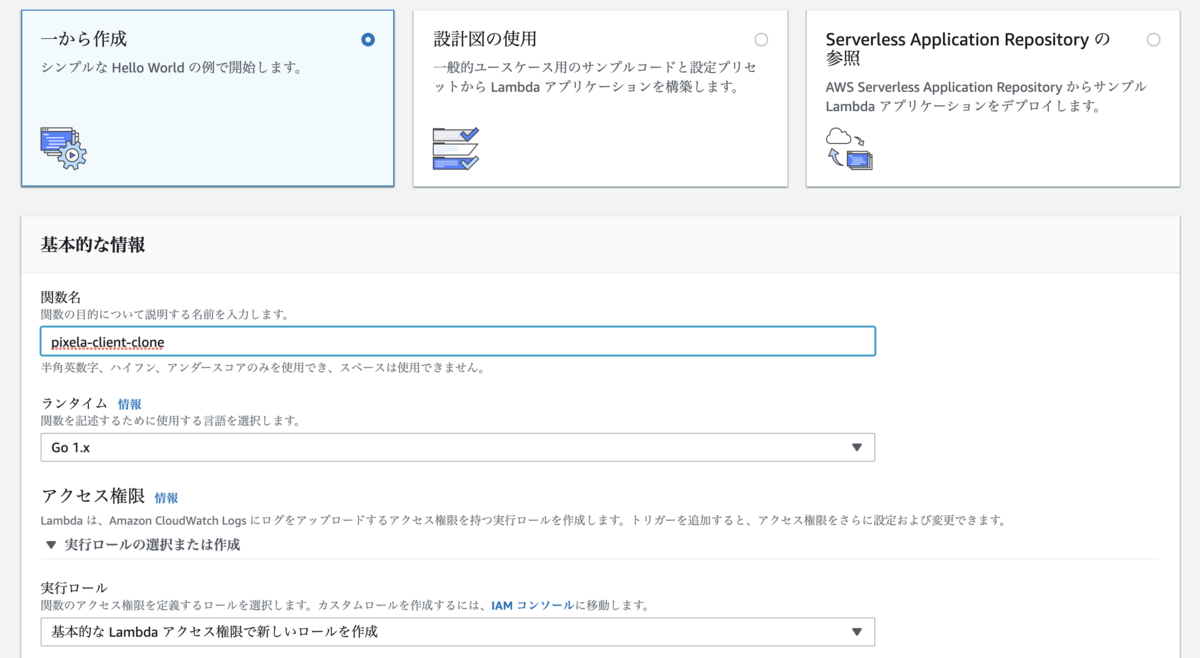
AWS コンソール を表示して Lambda > 関数 > 関数の作成 ボタンを押す。

一から作成 を選んで関数名を入力する。
ランタイムは Go 1.x を選んで実行ロールは 基本的な Lambda アクセス権限で新しいロールを作成 を選ぶ。
トリガーを追加
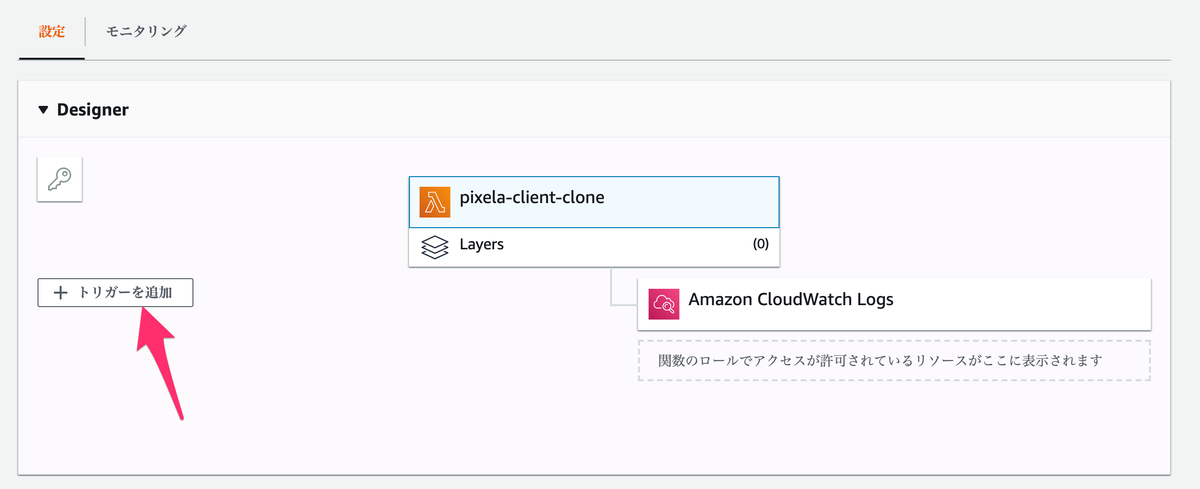
作成した関数を定期的に動かすためにトリガーを設定していく。
Designer の トリガーを追加 を押してトリガーの設定画面を表示する。
トリガーの設定画面は以下のように設定する。
- トリガーの選択は
CloudWatch Eventsを選択 - ルールは
新規ルールの作成を選択 - ルール名は
0100-utc-everydayを入力 - ルールタイプは
スケジュール式を選択 - スケジュール式は
cron(0 1 * * ? *)を入力
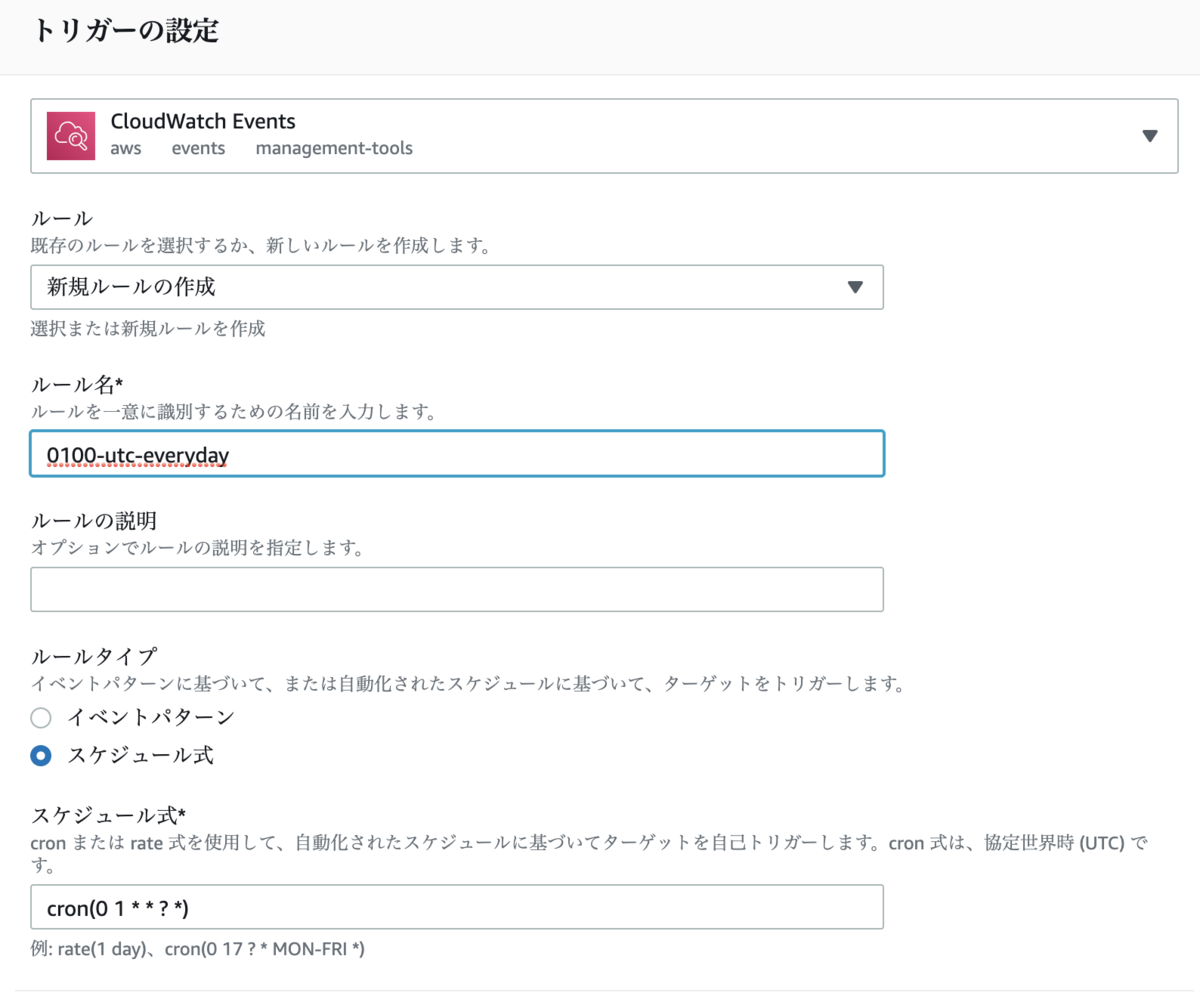
トリガーの有効化 にチェックを付けて 追加 ボタンを押す。

トリガーの設定はこれで完了。この設定をしておくと Lambda 関数が毎日1時 (UTC) に自動的に実行するようになる。
関数パッケージの作成
Lambda で動かす関数パッケージを作っていく。
以下のコードを main.go というファイル名で保存する。
package main import ( "context" "errors" "os" "strconv" "time" "github.com/aws/aws-lambda-go/lambda" "github.com/ebc-2in2crc/pixela-client-go" "github.com/google/go-github/github" "golang.org/x/oauth2" ) type MyEvent struct { Time time.Time `json:"time"` } const timeFormat = "20060102" var ( githubToken = os.Getenv("GITHUB_TOKEN") githubUser = os.Getenv("GITHUB_USER") githubRepo = os.Getenv("GITHUB_REPO") pixelaToken = os.Getenv("PIXELA_USER_TOKEN") userName = os.Getenv("PIXELA_USER_NAME") graphID = os.Getenv("PIXELA_GRAPH_ID") ) func main() { lambda.Start(HandleRequest) } func HandleRequest(event MyEvent) (string, error) { yesterday := event.Time.Truncate(time.Hour * 24).Add(-time.Hour * 24) cloneCount, err := retrieveCloneCount(yesterday) if err != nil { return "failed to retrieve clone count", err } if err := registerCloneCount(yesterday, cloneCount); err != nil { return "failed to register clone count", err } return "success", nil } func retrieveCloneCount(t time.Time) (int, error) { client := newGithubClient(githubToken) clones, resp, err := client.Repositories.ListTrafficClones( context.Background(), githubUser, githubRepo, &github.TrafficBreakdownOptions{Per: "day"}, ) if err != nil { return 0, err } _ = resp.Body.Close() d := t.Format(timeFormat) for _, c := range clones.Clones { if c.GetTimestamp().Format(timeFormat) == d { return c.GetCount(), nil } } return 0, nil } func newGithubClient(token string) *github.Client { oauthCli := oauth2.NewClient(context.Background(), oauth2.StaticTokenSource(&oauth2.Token{ AccessToken: token, })) return github.NewClient(oauthCli) } func registerCloneCount(date time.Time, cloneCount int) error { client := pixela.NewClient(userName, pixelaToken) pixel := client.Pixel(graphID) result, err := pixel.Create(date.Format(timeFormat), strconv.Itoa(cloneCount), "") if err != nil { return err } if result.IsSuccess == false { return errors.New(result.Message) } return nil }
AWS Lambda にアップロードする zip ファイルを作成する。
$ go build -o hello main.go && zip hello.zip hello adding: hello (deflated 53%)
Mac や Windows でコンパイルするときは GOOS=linux を付けて Linux 向けにクロスコンパイルする。
$ GOOS=linux go build -o hello main.go && zip hello.zip hello adding: hello (deflated 53%)
main.go がやっていること
ざっくり書くと「プログラムの実行日付の前日の Github リポジトリのクローン数を取得」して「プログラム実行日付の前日の (PIxela の) Pixel に記録」している。
当日のクローン数を当日の Pixel に記録したいときは yesterday := event.Time.Truncate(time.Hour * 24).Add(-time.Hour * 24) のあたりを適当にいじるとよい。
関数パッケージのアップロード
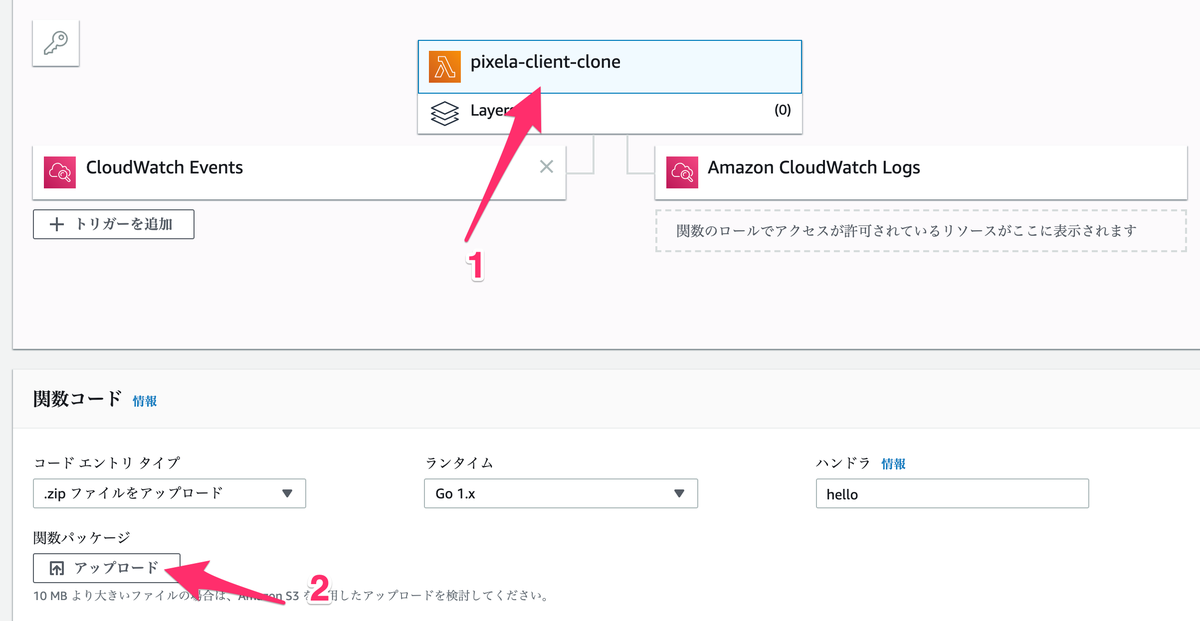
作成した zip ファイルを AWS にアップロードしていく。
コードエントリタイプは .zip ファイルをアップロード を選択して アップロード ボタンを押してさきほど作成した zip ファイルを AWS にアップロードする。
環境変数の設定
関数パッケージが使う環境変数を アップロード ボタンの下の 環境変数 に設定していく。
API トークンなど重要な情報を含んでいるので実際は暗号化するほうがよい。
| 環境変数名 | 設定する値 |
|---|---|
| GITHUB_TOKEN | Github の API トークン |
| GITHUB_USER | Github のユーザー名 |
| GITHUB_REPO | クローン数の草を生やしたいリポジトリ名 |
| PIXELA_USER_TOKEN | Pixela の API トークン |
| PIXELA_USER_NAME | Pixela のユーザー名 |
| PIXELA_GRAPH_ID | クローン数の草を生やす先のグラフの名前 |
これで Lambda 関数の作成は完了。 続いて Lambda 関数がちゃんと動くか確認していく。
Lambda 関数の動作確認
関数パッケージと環境変数が正しく設定されていて Lambda 関数がちゃんと動くかどうかを確認していく。
画面の上のほうにある テストイベントの設定 を押して テストイベントの設定 画面を表示する。

テストイベントの設定 画面は以下のように設定する。
新しいテストイベントの作成を選択- イベントテンプレートは
Hello Worldを選択 - イベント名は
testを入力
イベントの JSON は以下を設定する。
2019-08-13 のところはテストをしたい日付、たとえば Github リポジトリがクローンされたことが分かっている日、あるいは Github リポジトリがクローンされなかったことが分かっている日などを入力する。
{ "time": "2019-08-13T01:00:00Z" }
入力し終わったら 保存 ボタンを押してテストイベントを保存する。
次は作成したテストイベントを使って Lambda 関数の実際の動きを確認していく。
画面の上のほうにある テスト ボタンを押してテストイベント test を使って Lambda 関数を動かす。

実行結果: 成功 が表示されれば Lambda 関数は問題なく動いている。

以上。
参考ページ
EC2 インスタンスのメタデータを取得する ec2-metadatafs コマンドが便利すぎた。
AWS の EC2 インスタンスのメタデータを取得する ec2-metadatafs を使ってみたら便利すぎたのでメモ。
ec2-metadatafs ってなに?
ec2-metadatafs は AWS の EC2 インスタンスのメタデータを取得できるコマンド。
ec2-metadatafs の特徴は EC2 インスタンスのメタデータをファイルシステム上にマウントすることによって ls とか cat とか grep とかの CLI ツールと一緒に使うことが容易になること。
また、メタデータをファイルシステム上に配置するのでシェルの補完機能を最大限に活用することができるのがとても便利。
さっそく使ってみる。
$ mkdir metadata $ ec2-metadatafs --tags metadata/ 2019/08/12 05:38:35 [INFO] forked child with PID 3459 2019/08/12 05:38:35 [INFO] child process successfully mounted $ tree metadata/ metadata/ ├── dynamic │ └── instance-identity │ ├── document │ ├── pkcs7 │ ├── rsa2048 │ └── signature ├── meta-data │ ├── ami-id │ ├── ami-launch-index │ ├── ami-manifest-path │ ├── block-device-mapping │ │ ├── ami │ │ └── root │ ├── events │ ├── hostname │ ├── iam │ │ ├── info │ │ └── security-credentials │ │ └── ec2-describetag-role │ ├── identity-credentials │ ├── instance-action │ ├── instance-id │ ├── instance-type │ ├── local-hostname │ ├── local-ipv4 │ ├── mac │ ├── metrics │ ├── network │ │ └── interfaces │ │ └── macs │ │ └── 06:e5:0c:b8:f7:3e │ │ ├── device-number │ │ ├── interface-id │ │ ├── ipv4-associations │ │ ├── local-hostname │ │ ├── local-ipv4s │ │ ├── mac │ │ ├── owner-id │ │ ├── public-hostname │ │ ├── public-ipv4s │ │ ├── security-group-ids │ │ ├── security-groups │ │ ├── subnet-id │ │ ├── subnet-ipv4-cidr-block │ │ ├── vpc-id │ │ ├── vpc-ipv4-cidr-block │ │ └── vpc-ipv4-cidr-blocks │ ├── placement │ │ └── availability-zone │ ├── profile │ ├── public-hostname │ ├── public-ipv4 │ ├── public-keys │ │ └── 0 │ │ └── openssh-key │ ├── reservation-id │ ├── security-groups │ └── services │ ├── domain │ │ └── amazonaws.com │ └── partition └── tags ├── Tag1 └── Tag2
備忘録までにそれぞれのコマンドがやっていることを軽く書いておく。
まず metadata ディレクトリを作っているところ。
$ mkdir metadata
EC2 インスタンスのメタデータをマウントするディレクトリを作っている。 メタデータをマウントする場所はどこでもいいと思うけどユーザーが複数いてそれぞれのユーザーがメタデータを取得するのなら、メタデータはどのユーザーからも見える場所にマウントするとよいと思う。
次は ec2-metadatafs コマンドを実行しているところ。
$ ec2-metadatafs --tags metadata/ 2019/08/12 05:38:35 [INFO] forked child with PID 3459 2019/08/12 05:38:35 [INFO] child process successfully mounted
ec2-metadatafs コマンドを使って EC2 インスタンスのメタデータをさきほど作った metadata にマウントする。それだけ。
あと EC2 インスタンスのタグを取得するために --tags オプションを指定しているがタグは取得しないのなら指定する必要はない。
次は EC2 インスタンスのメタデータをマウントした metadata ディレクトリを tree してみたところ。
EC2 インスタンスのメタデータがファイルシステム上にマウントされているのがわかる。
$ tree metadata/
metadata/
├── dynamic
│ └── instance-identity
│ ├── document
│ ├── pkcs7
│ ├── rsa2048
│ └── signature
└── meta-data
├── ami-id
# 長いので省略
ec2-metadatafs を使ってみる
EC2 インスタンスのメタデータがファイルシステム上にマウントされる、ただそれだけのことなのだが実際に使ってみると想像以上に便利なのでいくつか使用例を書いておく。
試しにインスタンスタイプを取得してみる。
$ cat metadata/meta-data/instance-type t2.micro
簡単。
もう一つ試しに EC2 インスタンスが動いているアベイラビリティゾーンを取得してみる。
$ cat metadata/meta-data/placement/availability-zone ap-northeast-1a
すごく簡単。
ec2-metadatafs が便利なところはシェルの補完機能が働くので「あのメタデータどこだっけ?」ってときも雰囲気で入力して補完機能に任せる、みたいな使い方ができること。これが本当に便利。
補完機能を使うのすら面倒なときは find コマンドとかを使えば一切考える必要もない。
$$ find metadata/ -name "*zone*" metadata/meta-data/placement/availability-zone
繰り返すが便利。
あとタグを取得できるのが地味だけどかなり便利。
$ ls metadata/tags/
Tag1 Tag2
$ cat metadata/tags/Tag1
Tag1Value
EC2 インスタンスのメタデータを取得する方法はいろいろある
EC2 インスタンスのメタデータを取得する方法は ec2-metadatafs の他にもあるのでメモしておく。 それぞれがメリット・デメリットがあるので、状況によって使い分けるのがいいと思う。
http://169.254.169.254/latest/meta-data/
http://169.254.169.254/latest/meta-data/ にアクセスすると EC2 インスタンスのメタデータを取得できる。
$ curl http://169.254.169.254/latest/meta-data/ ami-id ami-launch-index ami-manifest-path block-device-mapping/ events/ hostname identity-credentials/ instance-action instance-id instance-type local-hostname local-ipv4 mac metrics/ network/ placement/ profile public-hostname public-ipv4 public-keys/ reservation-id security-groups services/
インスタンスタイプを取得してみる。
$ curl http://169.254.169.254/latest/meta-data/instance-type t2.micro
難しいことは一切ないが URL を打ち込むのが面倒くさいし URL を打ち間違えたときに 404 が返ってくるのがイラつく。コピペしたくなってくる。「あれ、インスタンスタイプの URL はなんだったっけ?」というときは http://169.254.169.254/latest/meta-data/ にアクセスして結果を眺めて「あ、instance-type だったな」とやる以外にないのが不便。
あと、どうやってもタグを取得できないのが地味に結構不便。
ただ、http://169.254.169.254/latest/meta-data/ の素晴らしいところは EC2 デフォルトの状態でも使えるということ。
あと、スクリプトの中からメタデータを取得したいときみたいなときは事前に知りたいメタデータの URL とかを調べているだろうし動作も確認しているだろうから、URL を打ち込むのが面倒くさいとか URL を打ち間違えたとかはないはず。
ec2-metadata コマンド
ec2-metadata は EC2 インスタンスのメタデータを取得するコマンド。
$ ec2-metadata --help ec2-metadata v0.1.2 Use to retrieve EC2 instance metadata from within a running EC2 instance. e.g. to retrieve instance id: ec2-metadata -i to retrieve ami id: ec2-metadata -a to get help: ec2-metadata --help For more information on Amazon EC2 instance meta-data, refer to the documentation at http://docs.amazonwebservices.com/AWSEC2/2008-05-05/DeveloperGuide/AESDG-chapter-instancedata.html Usage: ec2-metadata <option> Options: --all Show all metadata information for this host (also default). -a/--ami-id The AMI ID used to launch this instance -l/--ami-launch-index The index of this instance in the reservation (per AMI). -m/--ami-manifest-path The manifest path of the AMI with which the instance was launched. -n/--ancestor-ami-ids The AMI IDs of any instances that were rebundled to create this AMI. -b/--block-device-mapping Defines native device names to use when exposing virtual devices. -i/--instance-id The ID of this instance -t/--instance-type The type of instance to launch. For more information, see Instance Types. -h/--local-hostname The local hostname of the instance. -o/--local-ipv4 Public IP address if launched with direct addressing; private IP address if launched with public addressing. -k/--kernel-id The ID of the kernel launched with this instance, if applicable. -z/--availability-zone The availability zone in which the instance launched. Same as placement -c/--product-codes Product codes associated with this instance. -p/--public-hostname The public hostname of the instance. -v/--public-ipv4 NATted public IP Address -u/--public-keys Public keys. Only available if supplied at instance launch time -r/--ramdisk-id The ID of the RAM disk launched with this instance, if applicable. -e/--reservation-id ID of the reservation. -s/--security-groups Names of the security groups the instance is launched in. Only available if supplied at instance launch time -d/--user-data User-supplied data.Only available if supplied at instance launch time.
インスタンスタイプを取得してみる。
$ ec2-metadata --instance-type
instance-type: t2.micro
<メタデータの名前>: <メタデータの値> みたいな感じで出力されるので、メタデータの値たとえばインスタンスタイプの t2.micro の部分だけを取得するなら cut とかで切り出す感じ。ちょっと面倒くさい。
$ ec2-metadata --instance-type | cut -d ' ' -f 2 t2.micro
URL を打ち込む必要がないしショートオプションを使うとタイプ量はさらに少なくなるのが便利。 あと AMI が Amazon Linux ならデフォルトで使えるメリットが大きい。
ただ、メタデータの値を cut とかで切り出すのが面倒くさい。 あと、どうやってもタグを取得できないのが地味に結構不便。
ec2-metadatafs のインストール
ec2-metadatafs コマンドが便利な点と使い方の雰囲気は書いたのでインストール方法も書いておく。
といっても、curl で https://github.com/jszwedko/ec2-metadatafs/releases/download/<バージョン>/linux_amd64 からダウンロードして実行パーミッションを付けてパスが通ったところに置くだけ。
$ curl -sL https://github.com/jszwedko/ec2-metadatafs/releases/download/1.0.0/linux_amd64 > ec2-metadatafs $ chmod +x ec2-metadatafs $ sudo mv ec2-metadatafs /usr/bin/
ec2-metadatafs は EC2 メタデータをファイルシステム上にマウントするために FUSE に依存しているので FUSE をインストールしておく。
$ sudo yum install -y fuse
あとタグを取得するときは IAM ロールが必要になるのでつけておく。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeTags"], "Resource": ["*"] } ] }
IAM ロールを設定したくないときは ec2-metadatafs コマンドを使うときに --aws-access-key-id オプションとか --aws-secret-access-key とかを指定してあげてもいい。
ec2-metadatafs を使い終わったら
ec2-metadatafs を使い終わったらというか「あんまり便利じゃないしやっぱ使わなくていいや」というお気持ちになったときは EC2 インスタンスのメタデータをアンマウントしておく。
$ fusermount -u metadata
これだけ。
AWS CLI で意図していないプロファイルを使ってしまうのを防止するコマンドを書いたメモ。
AWS CLI で意図していないプロファイルを使ってしまうのを防止するコマンドを書いたメモ。
動機
AWS CLI はプロファイルを --profile オプションや AWS_DEFAULT_PROFILE 環境変数で指定できるようになっていて AWS アカウントや IAM ユーザーが複数あってもあまり手間なくいろいろな操作を行うことができる反面、使うプロファイルを間違うといとも簡単に悲惨なことが起こり得る。
日常の作業の多くは AWS アカウント向け / 操作対象の環境向けのスクリプトを書くなりして操作の入り口から分けてしまうなどの対策を取ればかなりの事故は減らせるが、ちょっとしたお試しとか突発的な作業をするときはどうしても生の aws コマンドを触ってしまいがちでどうしても事故が発生しやすくなってしまう。
そこで、AWS CLI を使うときに Github のリポジトリを消すときの Please type in the name of the repository to confirm. みたいに処理対象を入力させるシステムがあったら事故が減らせるのでは? と思った。
↓こういうやつ。

ラップコマンドの実行イメージ
実行イメージはこんな感じ。
AWS CLI のラップコマンド staging-hoge-aws を実行すると対象のアプリケーションと対象の環境を聞いてくる。この実行イメージは hoge が対象のアプリケーションで staging が環境。
staging-hoge-aws コマンドはコマンド内にハードコーディングされたアプリケーションおよび環境とユーザーが入力するアプリケーションおよび環境が 一致するときだけ実際の aws コマンドを実行する。この実行イメージは aws s3 ls が実際のコマンド。
$ staging-hoge-aws s3 ls
Enter target application name: hoge
Enter target environment name: staging
2019-07-27 11:13:21 xxx-bucket
2019-07-27 11:13:21 yyy-bucket
staging-hoge-aws コマンドはユーザーが入力するアプリケーションか環境が間違っているとメッセージを表示して実際のコマンドは実行しない。
$ staging-hoge-aws s3 ls
Enter target application name: fuga
Invalid application name: fuga
このラップコマンドはアプリケーションと環境の組み合わせ分を作っておく。
たとえば hoge アプリケーションは本番環境とステージング環境があるなら production-hoge-aws と staging-hoge-aws を作っておく。
本番環境用のラップコマンドはアプリケーションと環境の確認に加えて「本番環境をいじろうとしてるけど本当にいいの?」的なことを聞いてきてユーザーが yes を入力したときだけ実際の aws コマンドを実行する。ユーザーが yes 以外を入力したときは実際の aws コマンドは実行しない。
$ production-hoge-aws s3 ls Enter target application name: hoge Enter target environment name: production You will make changes to the production environment!!!!! Are you sure you want to continue (yes/no)?: yes # ユーザーが yes を入力したときだけ実際の aws コマンドが実行される 2019-07-27 11:13:21 xxx-bucket 2019-07-27 11:13:21 yyy-bucket
ラップコマンドの中身
staging-hoge-aws はこんな感じになっている。
単純に対象のアプリケーションと環境がハードコーディングしてあってユーザーの入力と一致するときに実際の aws コマンドを実行するだけ。
新しいアプリケーションあるいは環境用のコマンドをつくるときは TARGET_APP と TARGET_ENV だけ書き換える感じ。
#!/bin/bash TARGET_APP=hoge TARGET_ENV=staging PROFILE=${TARGET_ENV}-${TARGET_APP} echo -n 'Enter target application name: ' read APP_NAME if [ "${APP_NAME}" != "${TARGET_APP}" ]; then echo "Invalid application name: ${APP_NAME}" exit 1 fi echo -n 'Enter target environment name: ' read ENV_NAME if [ "${ENV_NAME}" != "${TARGET_ENV}" ]; then echo "Invalid environment name: ${ENV_NAME}" exit 1 fi if [ "${ENV_NAME}" == "production" ]; then echo "You will make changes to the production environment!!!!!" echo -n 'Are you sure you want to continue (yes/no)?: ' read CONFIRM if [ "${CONFIRM}" != "yes" ]; then exit 1 fi fi echo '' aws --profile $PROFILE "$@"
プロファイル
config ファイル
config ファイルはこんな感じにしておく。
[profile staging-hoge] output = json region = ap-northeast-1 [profile production-hoge] output = json region = ap-northeast-1
credentials ファイル
credentials ファイルはこんな感じにしておく。
[staging-hoge] aws_access_key_id = <ステージング環境のアクセスキー> aws_secret_access_key = <ステージング環境のシークレットキー> [production-hoge] aws_access_key_id = <本番環境のアクセスキー> aws_secret_access_key = <本番環境のシークレットキー>
参考にしたサイト
本番環境とステージング環境を取り違える事故を減らしたくて Twitter で聞いてみたら本職のインフラエンジニアから DevOps やってる人まで珠玉の知見を教えてもらいまくったのを参考にした。感謝しかない……っ!!